Lesson 1.2: Machine Learning Fundamentals
The machine learning process involves a series of steps that enable a machine to learn from data and make predictions or decisions. Below is a detailed explanation of each step:
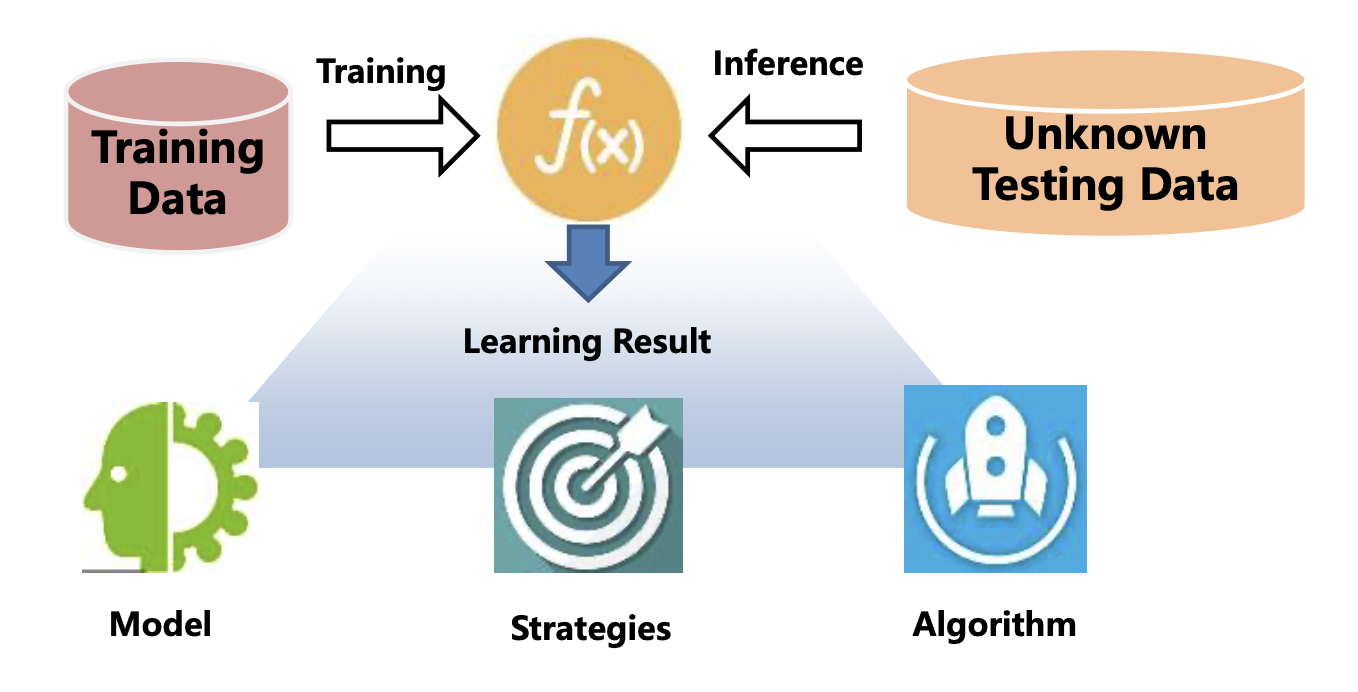
How The Machine Learns
-
Data Preprocessing:
- Data Cleaning: This step involves handling missing values, removing duplicates, and correcting inconsistencies in the dataset to ensure high-quality data for training.
- Data Sampling: Selecting a representative subset of data to reduce computational costs while maintaining the dataset's integrity.
- Data Splitting: Dividing the dataset into training, validation, and test sets to evaluate the model's performance effectively.
-
Feature Engineering:
- Feature Coding: Converting categorical data into numerical formats (e.g., one-hot encoding) to make it usable by machine learning algorithms.
- Feature Selection: Identifying and retaining the most relevant features to improve model performance and reduce overfitting.
- Feature Dimensionality Reduction: Techniques like Principal Component Analysis (PCA) are used to reduce the number of features while preserving essential information.
-
Data Modeling:
- Regression Problems: Predicting continuous values (e.g., house prices, temperature).
- Classification Problems: Predicting discrete labels (e.g., spam or not spam, disease diagnosis).
- Clustering Problems: Grouping similar data points into clusters based on patterns (e.g., customer segmentation).
-
Evaluation of Results:
- Accuracy: The percentage of correct predictions out of the total predictions made.
- Recall: The ability of the model to identify all relevant instances in the dataset.
- F1 Score: A balanced measure of precision and recall, useful for imbalanced datasets.
- PR Curve (Precision-Recall Curve): A graphical representation of the trade-off between precision and recall for different thresholds.
Machine Learning Methods
-
Supervised Learning:
- In supervised learning, the model is trained on a labeled dataset, where the input data is paired with the correct output.
- The goal is to learn a function (model) that maps inputs to outputs, enabling the model to predict outcomes for new, unseen data.
- Common Tasks:
- Classification: Predicting discrete labels (e.g., email spam detection, image recognition).
- Regression: Predicting continuous values (e.g., stock prices, weather forecasting).
-
Unsupervised Learning:
- In unsupervised learning, the model is trained on an unlabeled dataset, meaning there are no predefined outputs.
- The goal is to identify patterns, structures, or relationships within the data.
- Common Tasks:
- Clustering: Grouping similar data points into clusters (e.g., customer segmentation, document categorization).
Comparision of Machine Learning Algorithms
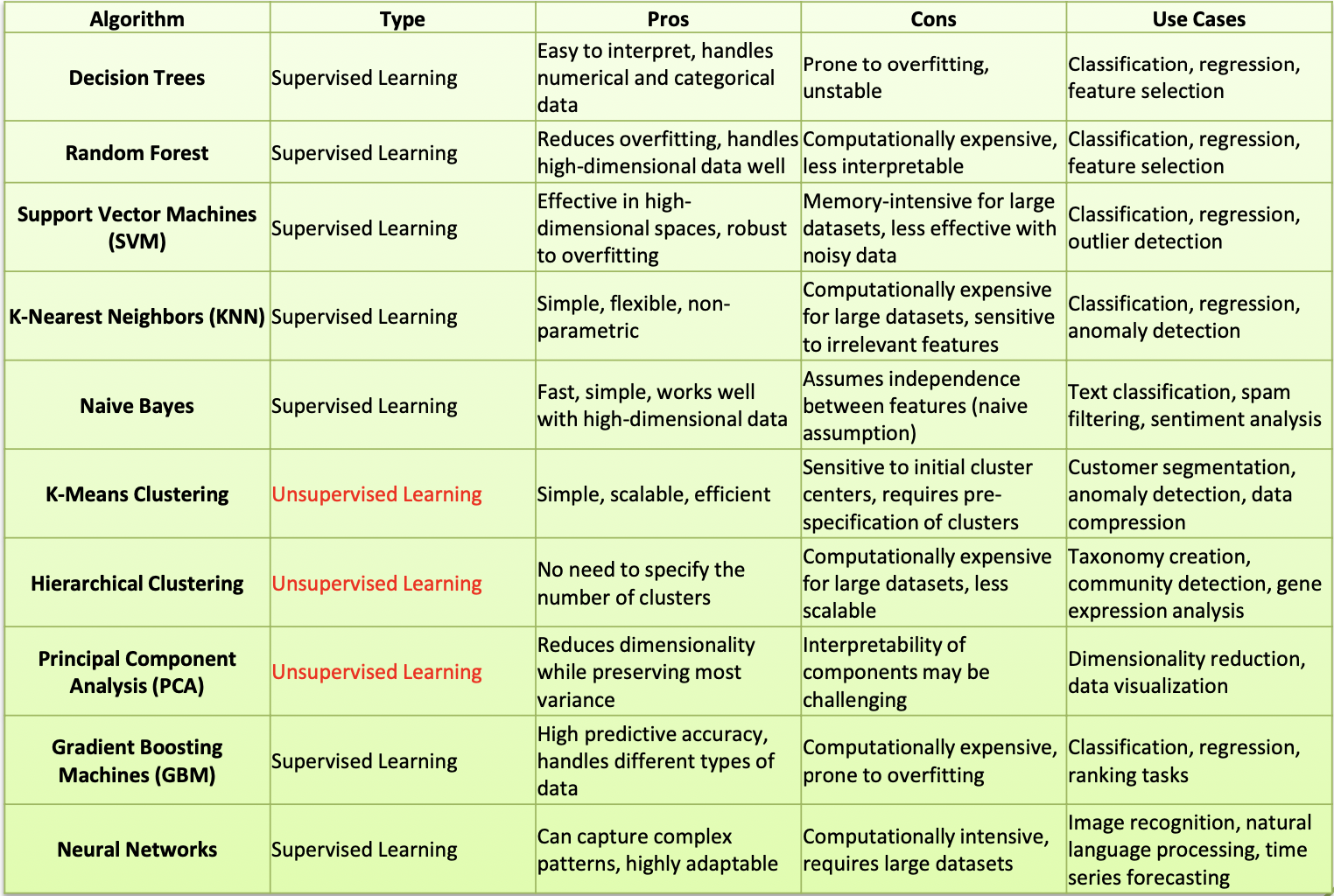
Classification Issues
Classification is a fundamental problem in supervised learning, where the goal is to predict discrete labels (categories) for new inputs based on patterns learned from labeled training data. The output variable in classification problems takes a finite number of discrete values, making it distinct from regression, where the output is continuous.
Types of Classification Problems
-
Binary Classification:
- In binary classification, the output variable has only two possible categories.
- Examples:
- Spam detection (spam or not spam).
- Disease diagnosis (disease present or not).
- Email classification (important or not important).
-
Multi-class Classification:
- In multi-class classification, the output variable can have three or more discrete categories.
- Examples:
- Handwritten digit recognition (classifying digits 0-9).
- Image classification (cat, dog, bird, etc.).
- Sentiment analysis (positive, negative, neutral).
Main Algorithms for Classification: Decision trees, Bayesian, SVM
Regression
A supervised learning technique to predict continuous numerical values (e.g., price, temperature) based on input variables. It finds relationships between variables so that predictions can be made. we have two types of variables present in regression:
- Dependent Variable (Target): The variable we are trying to predict e.g house price.
- Independent Variables (Features): The input variables that influence the prediction e.g locality, number of rooms.
Types of Regression
1. Binary Linear Regression
- Predicts an output using one input variable.
- Relationship modeled as a straight line:
- : Dependent variable (output).
- : Independent variable (input).
- : Slope (how much changes per unit ).
- : Intercept (value of when )
2. Multiple Linear Regression:
- Predicts an output using multiple input variables.
- Equation
- : Dependent variable.
- : Intercept (baseline value).
- : Coefficients (weights of input variables ).
Key Concepts
-
Loss Function: Mean Squared Error (MSE) is commonly used:
-
Optimization: Coefficients are adjusted using methods like Gradient Descent.
Advantages
- Simple to implement.
- Provides interpretable coefficients.
Disadvantages
- Assumes a linear relationship (not suitable for complex patterns).
- Sensitive to outliers.
Clustering
Clustering is an unsupervised learning technique that groups similar data points into clusters.
Types of Clustering
- K-Means Clustering
- Partitions data into clusters.
- Steps:
- Choose
- Initialize centroids randomly.
- Assign points to the nearest centroid.
- Update centroids.
- Repeat until convergence.
- Hierarchical Clustering
- Builds a tree of clusters (dendrogram).
- DBSCAN
- Groups points based on density.
Example
- Customer Segmentation: Grouping users by purchase behavior.