Perceptron model using PyTorch to learn the OR gate logic
Truth Table for OR Gate
| Output | ||
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
This code implements a Perceptron model using PyTorch to learn the OR gate logic. The OR gate is a simple binary classification problem where the output is 1 if at least one of the inputs is 1, and 0 otherwise. Below is a detailed explanation of the code:
Import Libraries
This part includes importing class from pytorch library.
import torch import torch.nn as nn import torch.optim as optim
torch:The main PyTorch library for tensor operations and neural networks.torch.nn:Contains neural network layers and loss functions.torch.optim:Provides optimization algorithms like Stochastic Gradient Descent (SGD).
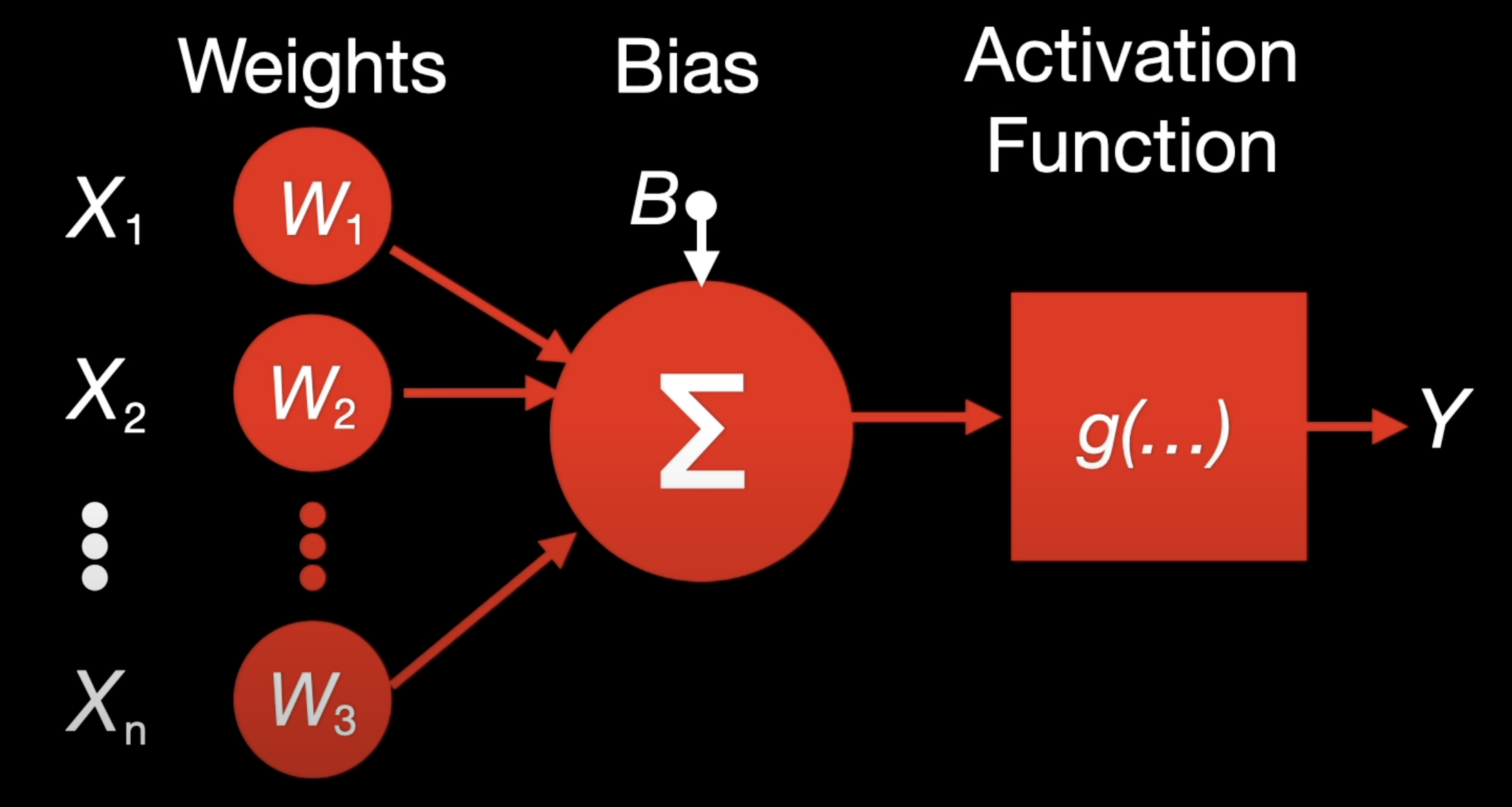
Define the Perceptron Model
This part creates a python class named Perceptron which will implement the logic gates between two inputs. The init constructor defines a single layer network with two inputs. To define the activation logic, a sigmoid function is defined in the forward method.
class Perceptron(nn.Module): def __init__(self, input_size): super(Perceptron, self).__init__() self.linear = nn.Linear(input_size, 1) # Single-layer perceptron. def forward(self, x): out = torch.sigmoid(self.linear(x)) # Sigmoid activation for binary output return out
Perceptron: A class that inherits from nn.Module, the base class for all neural network modules in PyTorch.nn.Linear(input_size, 1): Defines a fully connected (linear) layer with input_size input features and 1 output neuron.torch.sigmoid: Applies the sigmoid activation function to the output of the linear layer, squashing it to a value between 0 and 1 (useful for binary classification).
Initialize the Model, Loss Function, and Optimizer
input_size = 2 # OR gate has two input features model = Perceptron(input_size) criterion = nn.BCELoss() # Binary cross-entropy loss optimizer = optim.SGD(model.parameters(), lr=0.1) # Stochastic Gradient Descent optimizer
input_size = 2: The OR gate has two input featuresmodel = Perceptron(input_size): Creates an instance of the Perceptron model. Defining model object.nn.BCELoss(): Defines the Binary Cross-Entropy Loss function, which is used for binary classification tasks. Defining criterion object.optim.SGD: Uses theStochastic Gradient Descent (SGD)optimizer to update the model's parameters (weights and bias) during training. The learning rate is set to0.1. Defining optimizer object.
Prepare Training Data
data = torch.tensor([[0.0, 0.0], [0.0, 1.0], [1.0, 0.0], [1.0, 1.0]]) # Inputs labels = torch.tensor([[0.0], [1.0], [1.0], [1.0]]) # Expected outputs
-
data:A tensor containing the input features for the OR gate:[0.0, 0.0]:Both inputs are 0.[0.0, 1.0]:First input is 0, second input is 1.[1.0, 0.0]:First input is 1, second input is 0.[1.0, 1.0]:Both inputs are 1.
-
labels:A tensor containing the expected outputs for the OR gate:0.0: Output for[0.0, 0.0].1.0: Output for all other inputs.
Train the Perecptron
This part trains the model using training data and the labels. Here epoch is defined.
epochs = 1000 for epoch in range(epochs): model.train() # Set the model to training mode # Forward pass outputs = model(data) loss = criterion(outputs, labels) # Backward pass and optimization optimizer.zero_grad() loss.backward() optimizer.step() if (epoch + 1) % 100 == 0: print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
epochs = 1000:The number of times the model will see the entire dataset.model.train():Sets the model to training mode (important for layers like dropout or batch normalization).- Forward Pass:
outputs = model(data): Computes the predicted outputs for the input data.loss = criterion(outputs, labels): Calculates the loss between the predicted outputs and the true labels.
- Backward Pass:
optimizer.zero_grad(): Clears the gradients from the previous iteration.loss.backward(): Computes the gradients of the loss with respect to the model's parameters.optimizer.step(): Updates the model's parameters using the computed gradients.
- Logging:
- Prints the loss every 100 epochs to monitor training progress.
Test the trained model
model.eval() # Set the model to evaluation mode with torch.no_grad(): test_output = model(data) predicted = test_output.round() # Round to get binary output print(f'Predicted outputs for OR gate:\n{predicted}')
model.eval(): Sets the model to evaluation mode (disables layers like dropout or batch normalization).torch.no_grad(): Disables gradient computation for inference (reduces memory usage and speeds up computation).test_output = model(data): Computes the outputs for the input data using the trained model.predicted = test_output.round(): Rounds the outputs to 0 or 1 to get binary predictions.print(predicted): Displays the predicted outputs for the OR gate.
Output:
It can be seen that the loss is reducing in each interval. After training, the model should correctly predict the outputs for the OR gate:
(.venv) term@mac AI_Codes $ python3 Perceptron/or_gate.py Epoch [100/1000], Loss: 0.3822 Epoch [200/1000], Loss: 0.2925 Epoch [300/1000], Loss: 0.2347 Epoch [400/1000], Loss: 0.1949 Epoch [500/1000], Loss: 0.1661 Epoch [600/1000], Loss: 0.1443 Epoch [700/1000], Loss: 0.1272 Epoch [800/1000], Loss: 0.1136 Epoch [900/1000], Loss: 0.1025 Epoch [1000/1000], Loss: 0.0932 Predicted outputs for OR gate: tensor([[0.], [1.], [1.], [1.]])