Lesson 1.4: Neural Networks
Neural networks are machine learning models that mimic the complex functions of the human brain. These models consist of interconnected nodes or neurons that process data, learn patterns, and enable tasks such as pattern recognition and decision-making.
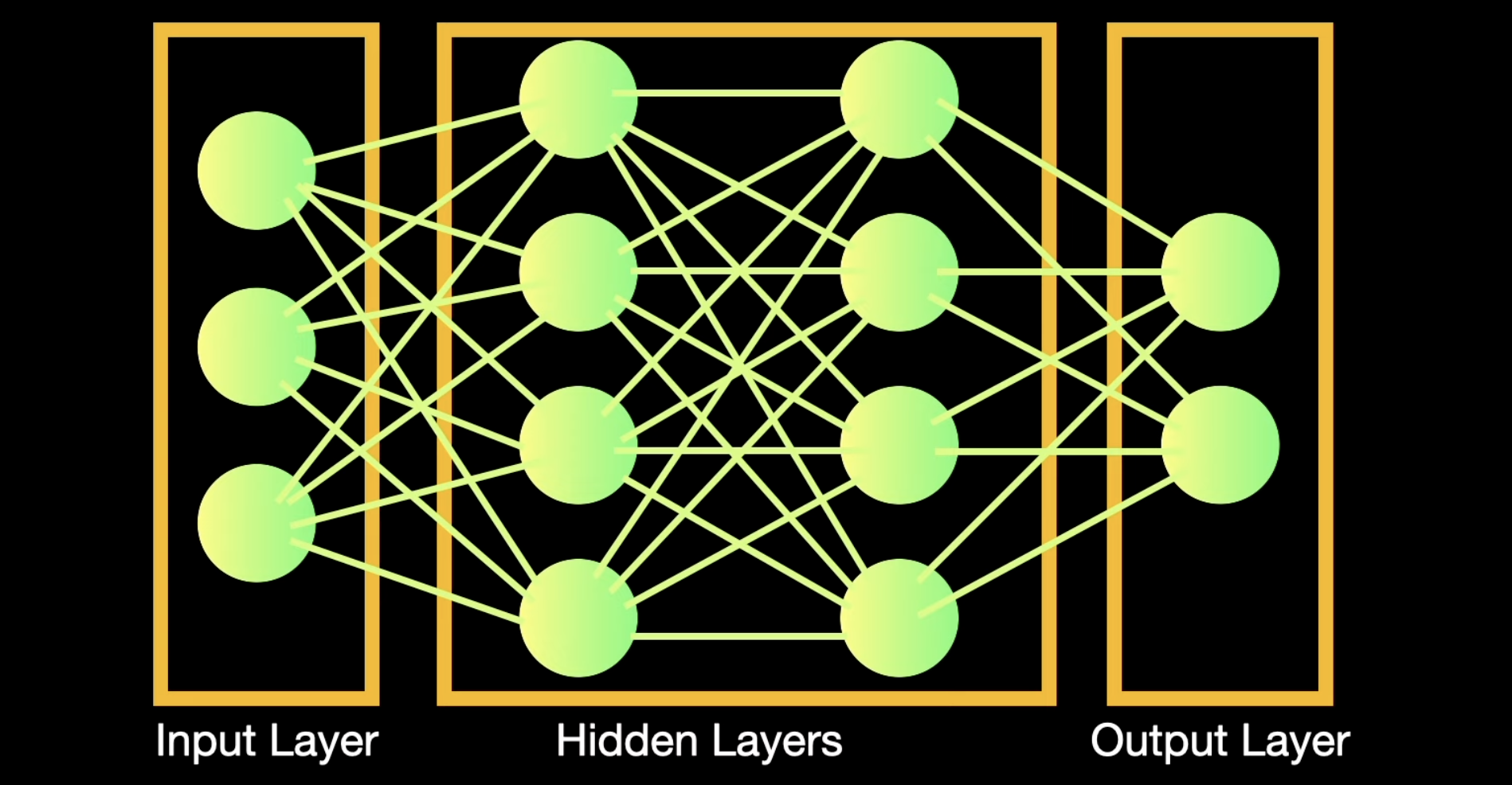
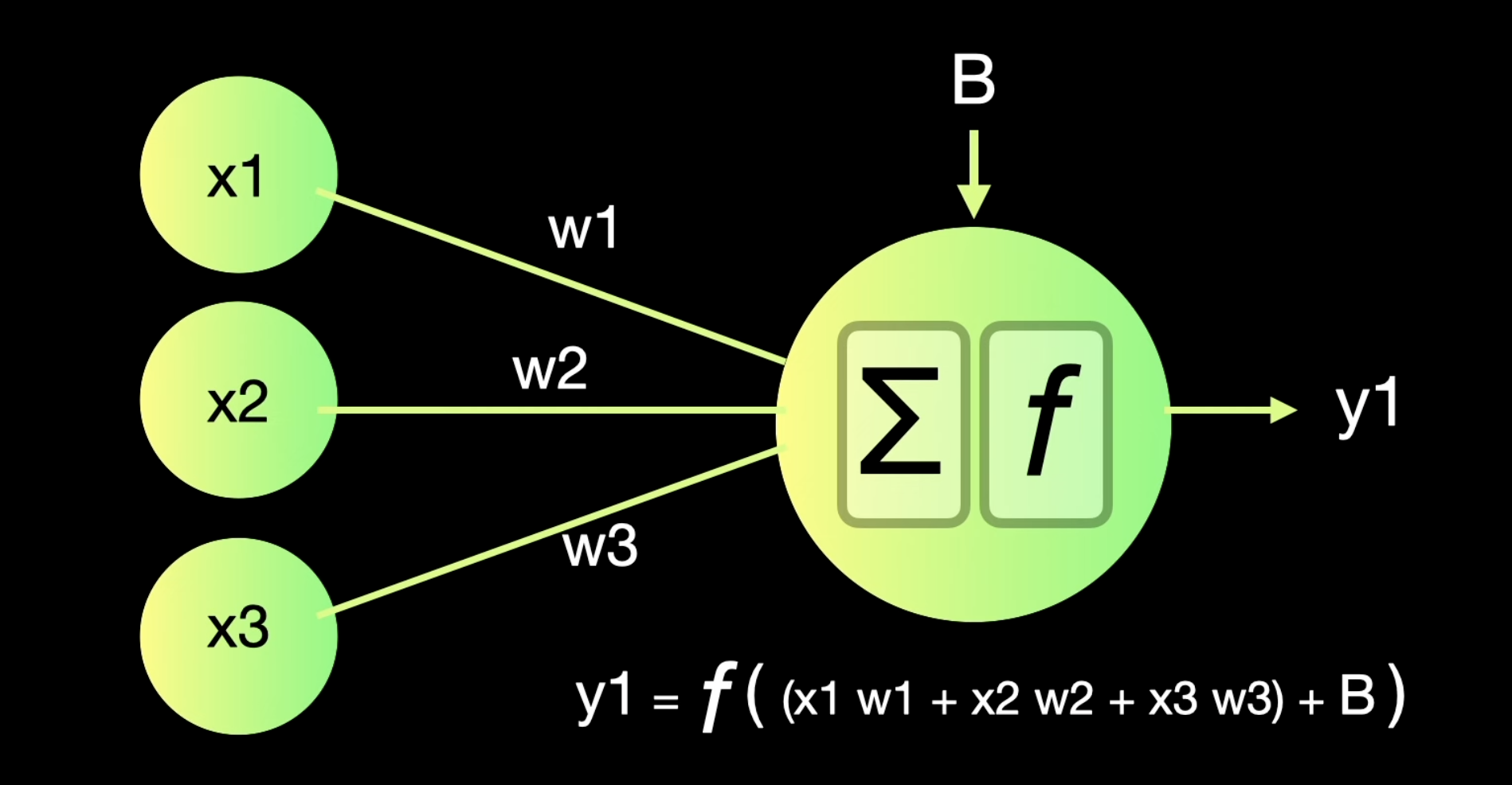
Neural networks are capable of learning and identifying patterns directly from data without pre-defined rules. These networks are built from several key components:
- Neurons: The basic units that receive inputs, each neuron is governed by a threshold and an activation function.
- Connections: Links between neurons that carry information, regulated by weights and biases.
- Weights and Biases: These parameters determine the strength and influence of connections.
- Propagation Functions: Mechanisms that help process and transfer data across layers of neurons.
- Learning Rule: The method that adjusts weights and biases over time to improve accuracy.
Learning in neural networks follows a structured, three-stage process:
- Input Computation: Data is fed into the network.
- Output Generation: Based on the current parameters, the network generates an output.
- Iterative Refinement: The network refines its output by adjusting weights and biases, gradually improving its performance on diverse tasks.
Layers in Neural Network Architecture
Input Layer:
- This is where the network receives its input data. Each input neuron in the layer corresponds to a feature in the input data.
- The input layer consists of neurons (or nodes), each representing a feature of the input data.
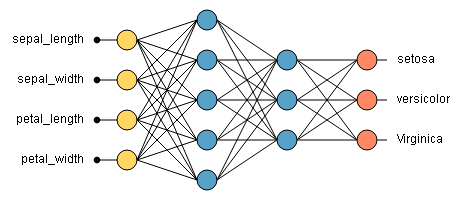
- For example, if the input is an image with 784 pixels (e.g., a 28x28 grayscale image), the input layer will have 784 neurons, each representing one pixel value.
- The input layer does not perform any computation; it simply passes the data to the first hidden layer.
Hidden Layers:
- These layers perform most of the computational heavy lifting. A neural network can have one or multiple hidden layers. Each layer consists of units (neurons) that transform the inputs into something that the output layer can use.
- Each hidden layer consists of neurons that perform two key operations:
- Weighted Sum: Compute the weighted sum of inputs from the previous layer
- Activation Function: Apply a non-linear activation function (e.g., ReLU, sigmoid, tanh) to introduce non-linearity
- The output of each neuron in the hidden layer is passed to the next layer.
- Multiple hidden layers allow the network to learn hierarchical features:
- Early layers learn simple patterns (e.g., edges in an image).
- Deeper layers learn complex patterns (e.g., shapes, objects).
- Each hidden layer consists of neurons that perform two key operations:
Output Layer:
- The final layer produces the output of the model. The format of these outputs varies depending on the specific task (e.g., classification, regression). The output layer consists of neurons that represent the final output of the network.
- The number of neurons in the output layer depends on the task:
- Binary Classification: 1 neuron (outputs a probability between 0 and 1).
- Multi-Class Classification: neurons (one for each class, outputs probabilities for each class).
- Regression: 1 neuron (outputs a continuous value).
- The output layer computes the weighted sum of inputs from the last hidden layer and applies an appropriate activation function:
- Sigmoid: For binary classification (outputs a probability between 0 and 1).
- Softmax: For multi-class classification (outputs probabilities for each class).
- Linear/Identity: For regression (outputs a continuous value).
- The number of neurons in the output layer depends on the task:
Working of Neural Networks
Forward Propagation
When data is input into the network, it passes through the network in the forward direction, from the input layer through the hidden layers to the output layer. This process is known as forward propagation. Here’s what happens during this phase:
- Linear Transformation: Each neuron in a layer receives inputs, which are multiplied by the weights associated with the connections. These products are summed together, and a bias is added to the sum. This can be represented mathematically as:
- where
- represents the weights,
- represents the inputs, and
- is the bias is then passed through an activation function. The activation function is crucial because it introduces non-linearity into the system, enabling the network to learn more complex patterns. Popular activation functions include ReLU, sigmoid, and tanh.
- Activation: The result of the linear transformation (denoted as ) is then passed through an activation function. The activation function is crucial because it introduces non-linearity into the system, enabling the network to learn more complex patterns. Popular activation functions include ReLU, sigmoid, and tanh.
Backpropagation
After forward propagation, the network evaluates its performance using a loss function, which measures the difference between the actual output and the predicted output. The goal of training is to minimize this loss. This is where backpropagation comes into play:
- Loss Calculation: The network calculates the loss, which provides a measure of error in the predictions. The loss function could vary; common choices are mean squared error for regression tasks or cross-entropy loss for classification.
- Gradient Calculation: The network computes the gradients of the loss function with respect to each weight and bias in the network. This involves applying the chain rule of calculus to find out how much each part of the output error can be attributed to each weight and bias.
- Weight Update: Once the gradients are calculated, the weights and biases are updated using an optimization algorithm like stochastic gradient descent (SGD). The weights are adjusted in the opposite direction of the gradient to minimize the loss. The size of the step taken in each update is determined by the learning rate.
Iteration
This process of forward propagation, loss calculation, backpropagation, and weight update is repeated for many iterations over the dataset. Over time, this iterative process reduces the loss, and the network’s predictions become more accurate.
Through these steps, neural networks can adapt their parameters to better approximate the relationships in the data, thereby improving their performance on tasks such as classification, regression, or any other predictive modeling.
Example Problem: Predicting the effectiveness of a drug dosage.
- Dosages: Low (0), Medium (1), High (0).
- Goal: Predict whether a future dosage will be effective.
- Challenge: A straight line cannot accurately predict all three dosages.
- Solution: A neural network can fit a "squiggle" (non-linear function) to the data, allowing it to model complex relationships.
let's imagine we tested a drug that was designed to treat an illness and we gave the drug to three different groups of people, with three different dosages: low, medium, and high.
- The low dosages were not effective so we set them to 0 on this graph.
- The medium dosages were effective so we set them to 1.
- The high dosages were not effective, so those are set to 0. now that we have this data, we would like to use it to predict whether or not a future dosage will be effective.
Structure of a Neural Network
- Nodes and Connections:
- A neural network consists of nodes (neurons) and connections (synapses) between them.
- Each connection has a weight (parameter) that is estimated during training.
- Activation Functions:
- Nodes in the hidden layers use activation functions to introduce non-linearity.
- Common activation functions:
- Softplus:
- ReLU (Rectified Linear Unit):
- Sigmoid:
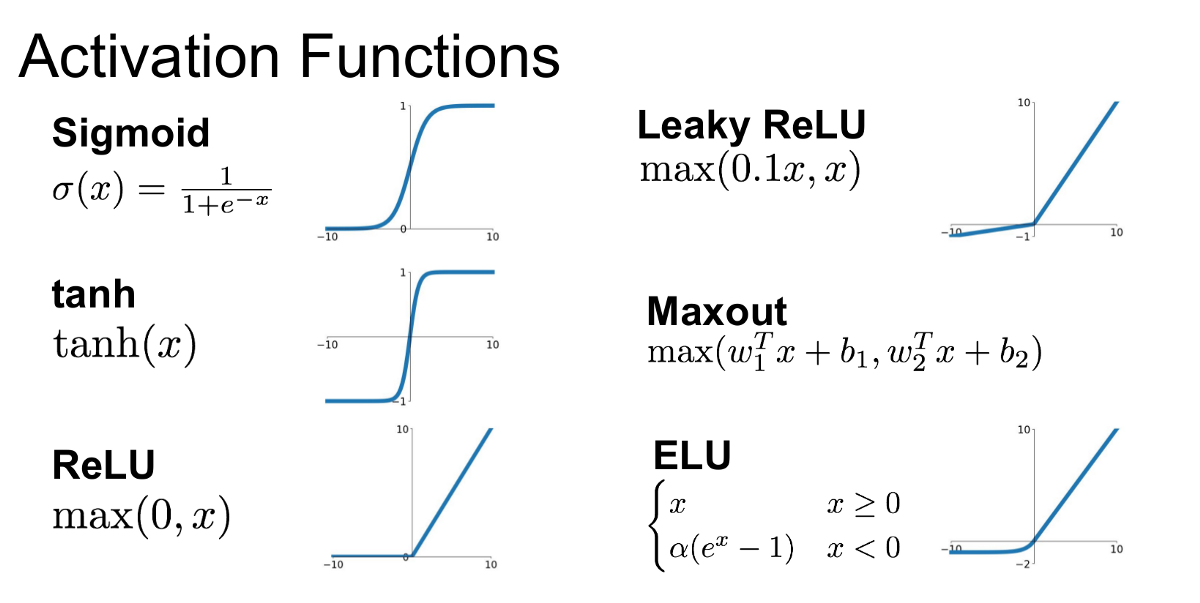
Neural Network Components
-
Input Layer:
- Contains the input features (e.g., drug dosage).
-
Hidden Layers:
- Layers between the input and output layers.
- Each node in the hidden layer applies an activation function to a weighted sum of its inputs.
-
Output Layer:
- Produces the final prediction (e.g., drug effectiveness).
It only has one input node, where we plug in the dosage, only one output node to tell us the predicted effectiveness, and only two nodes between the input and output nodes. These layers of nodes between the input and output nodes are called hidden layers. When you build a neural network one of the first things you do is decide how many hidden layers you want and how many nodes go into each hidden layer. Although there are rules of thumb for making decisions about the hidden layers, you essentially make a guess and see how well the neural network performs, adding more layers and nodes if needed. Now, even though this neural network looks fancy, it is still made from the same parts used in this simple neural network, which has only one hidden layer with two nodes.
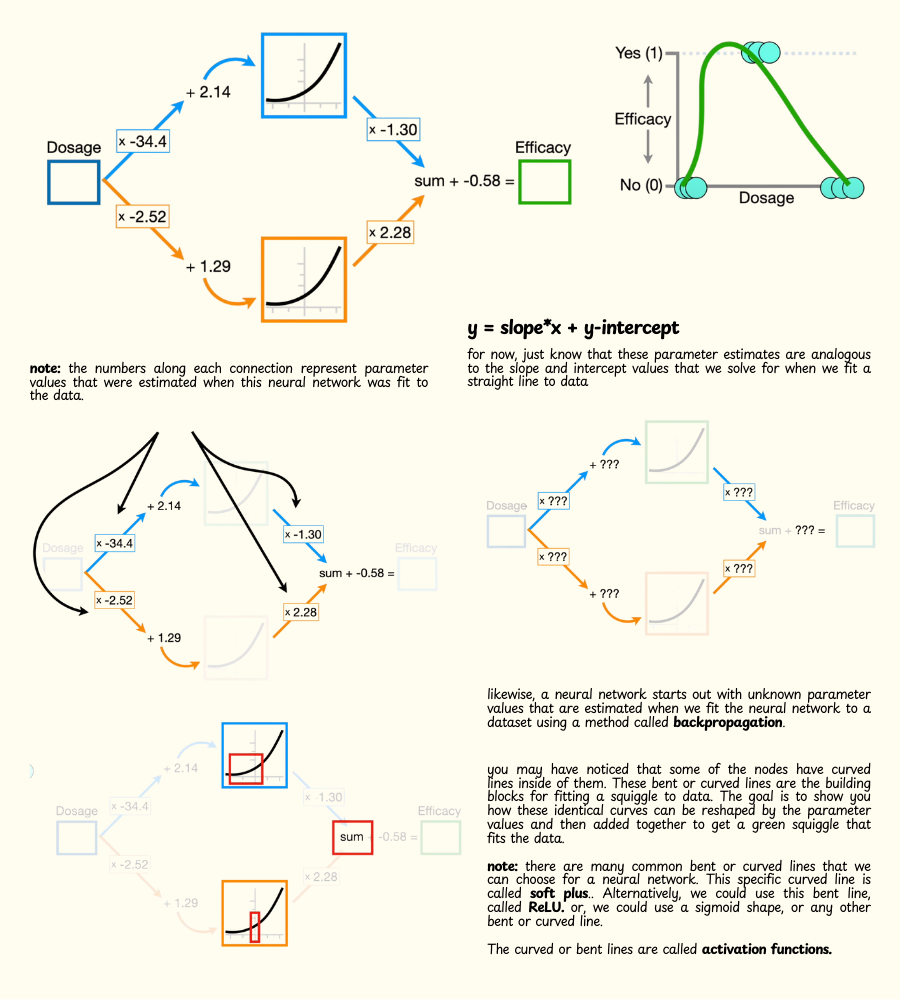
- A neural network starts out with unknown parameter values that are estimated when we fit the neural network to a dataset using a method called backpropagation. but, for now, just assume that we've already fit this neural network to this specific dataset, and that means we have already estimated these parameters.
- Also, you may have noticed that some of the nodes have curved lines inside of them, these bent or curved lines are the building blocks for fitting a squiggle to data.
- The goal of this example is to show you how these identical curves can be reshaped by the parameter values and then added together to get a green squiggle that fits the data.
- Note: There are many common bent or curved lines that we can choose for a neural network. This specific curved line is called soft plus. Alternatively, we could use this bent line, called ReLU or, we could use a sigmoid shape, or any other bent or curved line. Thes curved or bent lines are called activation functions.
BLUE CURVE
- Note: To keep the math simple, let's assume dosages go from zero, for low, to one, for high.
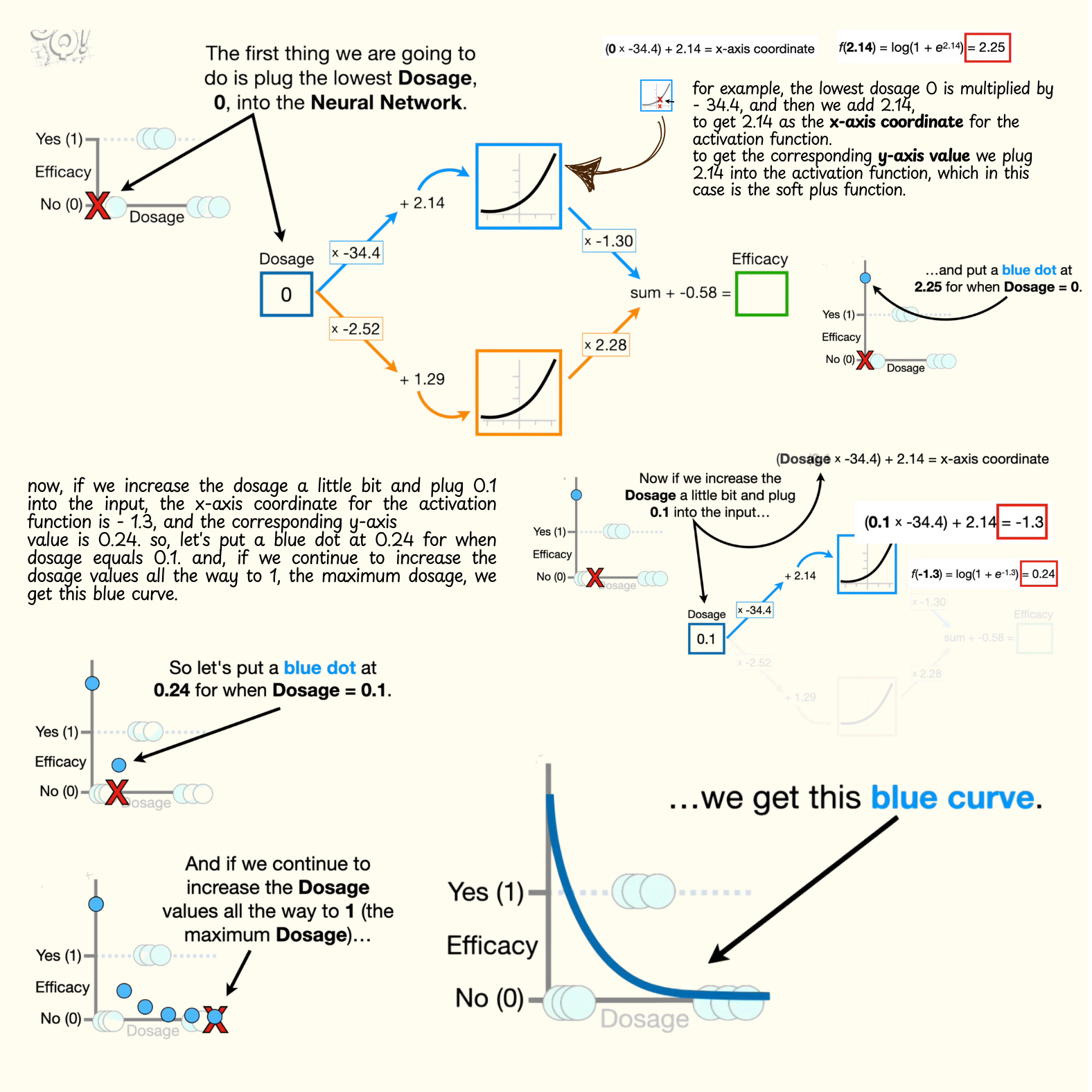
- The first thing we are going to do is plug the lowest dosage, zero, into the neural network.
- To get from the input node to the top node in the hidden layer, this connection multiplies the dosage by negative 34.4 and then adds 2.14, and the result is an x-axis coordinate for the activation function.
- The lowest dosage 0 is multiplied by negative 34.4, and then we add 2.14, to get 2.14 as the x-axis coordinate for the activation function.
- To get the corresponding y-axis value we plug 2.14 into the activation function, which in this case is the soft plus function. Note: if we had chosen the sigmoid curve for the activation function then we would plug 2.14 into the equation for the sigmoid curve, and if we had chosen the ReLU bent line for the activation function, then we would plug 2.14 into the ReLU equation.
- The log of one plus e raised to the 2.14 power is 2.25.
- note: in statistics, machine learning, and most programming languages, the log function implies the natural log, or the log base e. anyway, the y-axis coordinate for the activation function is 2.25, so let's extend this y-axis up a little bit and put a blue dot at 2.25 for when dosage equals zero.
- Now, if we increase the dosage a little bit and plug 0.1 into the input, the x-axis coordinate for the activation function is negative 1.3, and the corresponding y-axis value is 0.24. so, let's put a blue dot at 0.24 for when dosage equals 0.1.
- if we continue to increase the dosage values all the way to 1, the maximum dosage, we get this blue curve.
- Note: before we move on I want to point out that the full range of dosage values, from 0 to 1, corresponds to this relatively narrow range of values from the activation function. in other words, when we plug dosage values, from 0 to 1, into the neural network, and then multiply them by negative 34.4 and add 2.14, we only get x-axis coordinates that are within the red box. and thus, only the corresponding y-axis values in the red box are used to make this new blue curve.
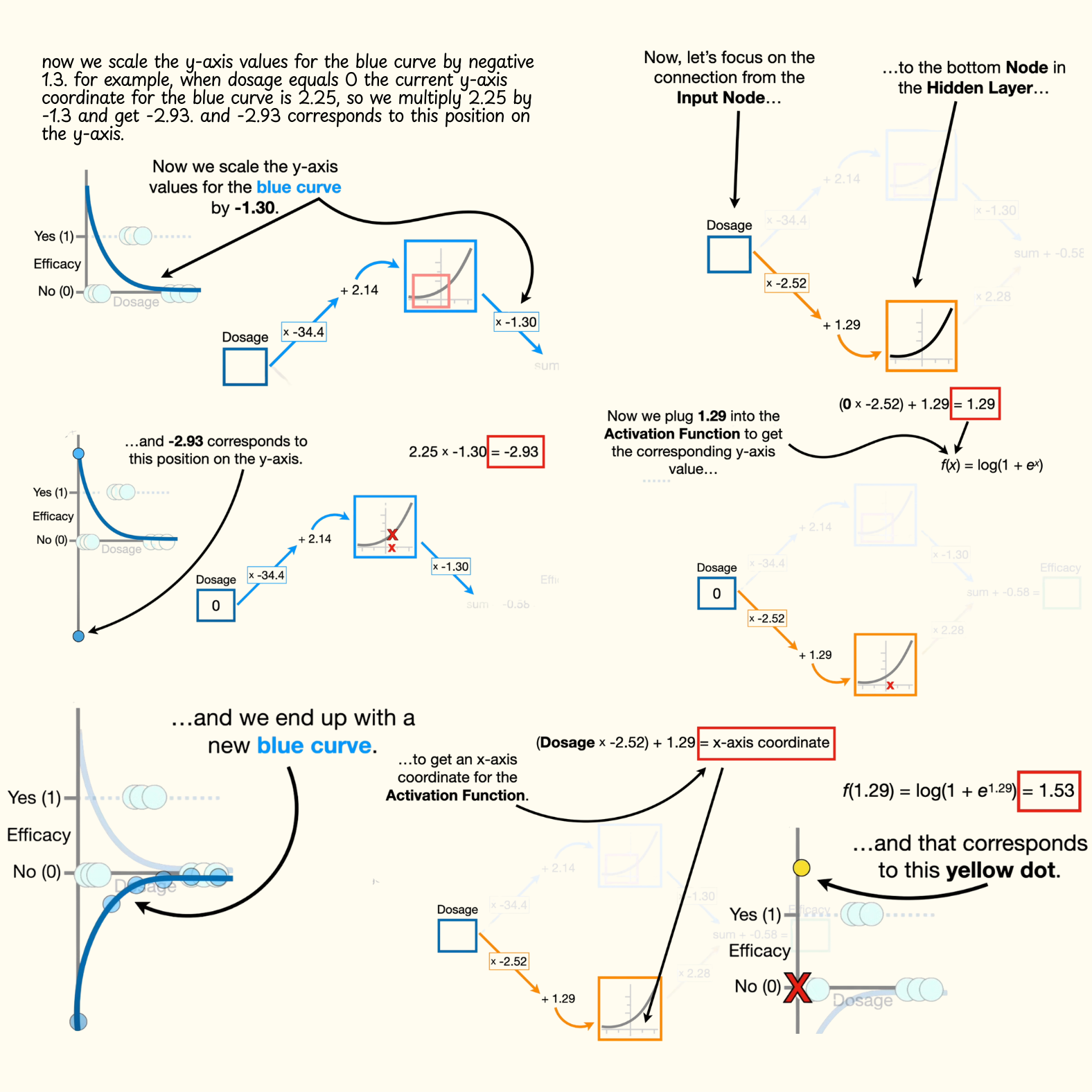
- Now we scale the y-axis values for the blue curve by negative 1.3. for example, when dosage equals zero the current y-axis coordinate for the blue curve is 2.25, so we multiply 2.25 by negative 1.3 and get negative 2.93. and negative 2.93 corresponds to this position on the y-axis. likewise, we multiply all of the other y-axis coordinates on the blue curve by negative 1.3 and we end up with a new blue curve.
YELLOW CURVE
- Now, let's focus on the connection from the input node, to the bottom node in the hidden layer. however, this time, we multiply the dosage by negative 2.52, instead of negative 34.4, and we add 1.29, instead of 2.14, to get the x-axis coordinate for the activation function. remember, these values come from fitting the neural network to the data with backpropagation, and we'll talk about that in part two in this series.
- Now, if we plug the lowest dosage, zero, into the neural network, then the x-axis coordinate for the activation function is 1.29.
- Now we plug 1.29 into the activation function to get the corresponding y-axis value, and get 1.53. and that corresponds to this yellow dot.
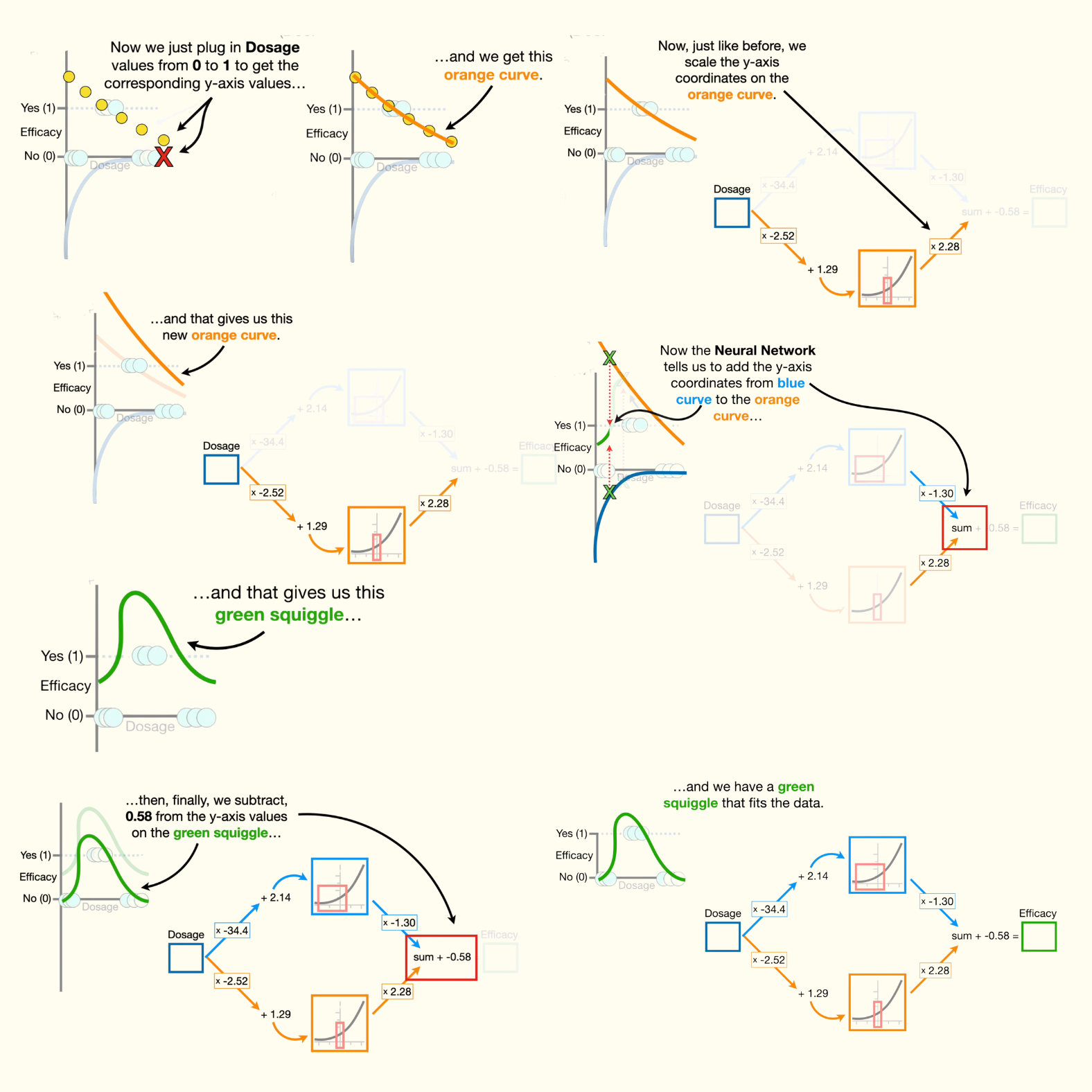
- Now, we just plug in dosage values from 0 to 1 to get the corresponding y-axis values, and we get this orange curve.
- Note: Just like before, i want to point out that the full range of dosage values, from 0 to 1, corresponds to this narrow range of values from the activation function. in other words, when we plug dosage values from 0 to 1 into the neural network we only get x-axis coordinates that are within the red box and thus, only the corresponding y-axis values in the red box are used to make this new orange curve.
- So we see that fitting a neural network to data gives us different parameter estimates on the connections and that results in each node in the hidden layer using different portions of the activation functions to create these new and exciting shapes. now, just like before, we scale the y-axis coordinates on the orange curve, only this time we scale by a positive number: 2.28.
GREEN SQUIGGLE
- Now the neural network tells us to add the y-axis coordinates from the blue curve to the orange curve, and that gives us this green squiggle.
- Then, finally, we subtract 0.58 from the y-axis values on the green squiggle, and we have a green squiggle that fits the data.
- Now, if someone comes along and says that they are using dosage equal to 0.5 we can look at the corresponding y-axis coordinate on the green squiggle and see that the dosage will be effective. or, we can solve for the y-axis coordinate by plugging dosage equals 0.5 into the neural network, and do the math.
Now, if you've made it this far you may be wondering why this is called a neural network. instead of a big fancy squiggle fitting machine. the reason is that way back in the 1940s and 50s, when neural networks were invented, they thought the nodes were vaguely like neurons, and the connections between the nodes were sort of like synapses however, i think they should be called big fancy squiggle fitting machines, because that's what they do.
- Note: whether or not you call it a squiggle fitting machine, the parameters that we multiply are called weights, and the parameters that we add are called biases.
- Note: this neural network starts with two identical activation functions, but the weights and biases on the connections slice them, flip them, and stretch them into new shapes, which are then added together to get a squiggle that is entirely new and then the squiggle is shifted to fit the data.
- Now, if we can create this green squiggle with just two nodes in a single hidden layer, just imagine what types of green squiggles we could fit with more hidden layers and more nodes in each hidden layer. in theory, neural networks can fit a green squiggle to just about any dataset, no matter how complicated, and i think that's pretty cool.
Backpropagation
So let's talk about how backpropagation optimizes the weights and biases in this, and other, neural networks. In this part we talk about the main ideas of backpropagation.
- Using the chain rule to calculate derivatives
- Plugging the derivatives
First, so we can be clear about which specific weights we are talking about, let's give each one a name: we have w1, w2, w3, and w4 and let's name each bias: b1, b2, and b3.
- Note: conceptually, backpropagation starts with the last parameter and works its way backwards to estimate all of the other parameters. However, we can discuss all of the main ideas behind a backpropagation by just estimating the last bias, b3. So, in order to start from the back, let's assume that we already have optimal values for all of the parameters except for the last bias term, b3.
- Note: throughout this, I'll make the parameter values that have already been optimized green, and unoptimized parameters will be red.
- Note: To keep the math simple, let's assume dosages go from 0, for low, to 1, for high.
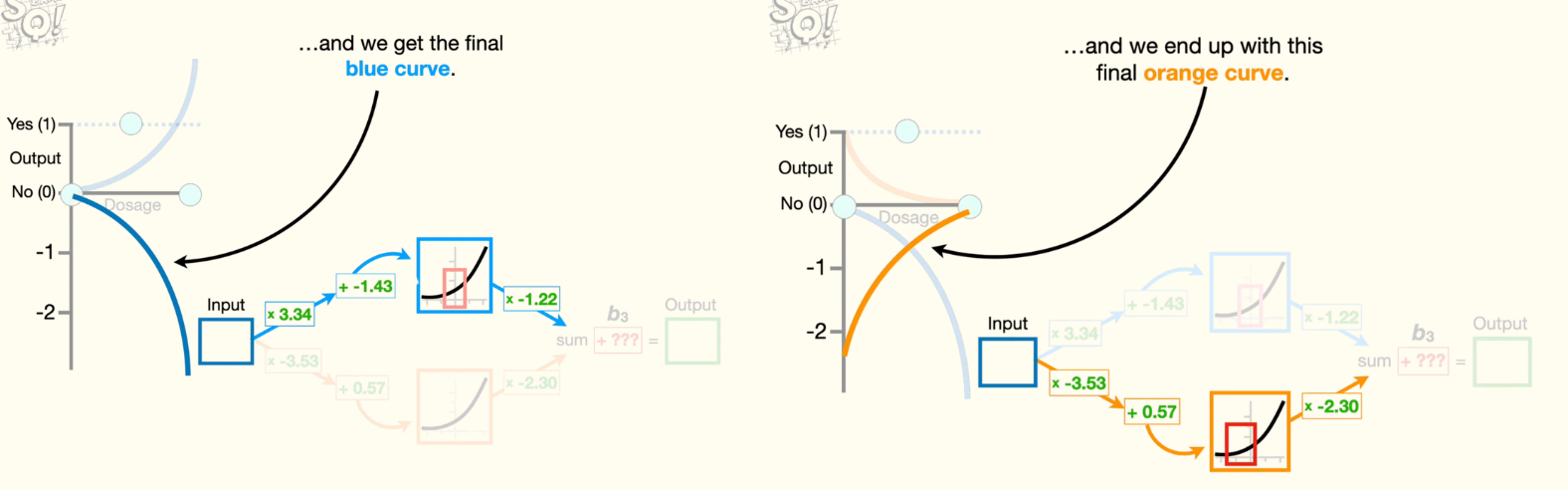
Then we multiply the y-axis coordinates on the blue curve by negative 1.22 and we get the final blue curve. Now, if we run dosages from zero to one through the connection to the bottom node in the hidden layer, then we get x-axis coordinates inside this red box. Now we plug those x-axis coordinates into the activation function to get the corresponding y-axis coordinates for this orange curve.
Now we multiply the y-axis coordinates on the orange curve by negative 2.3 and we end up with this final orange curve.
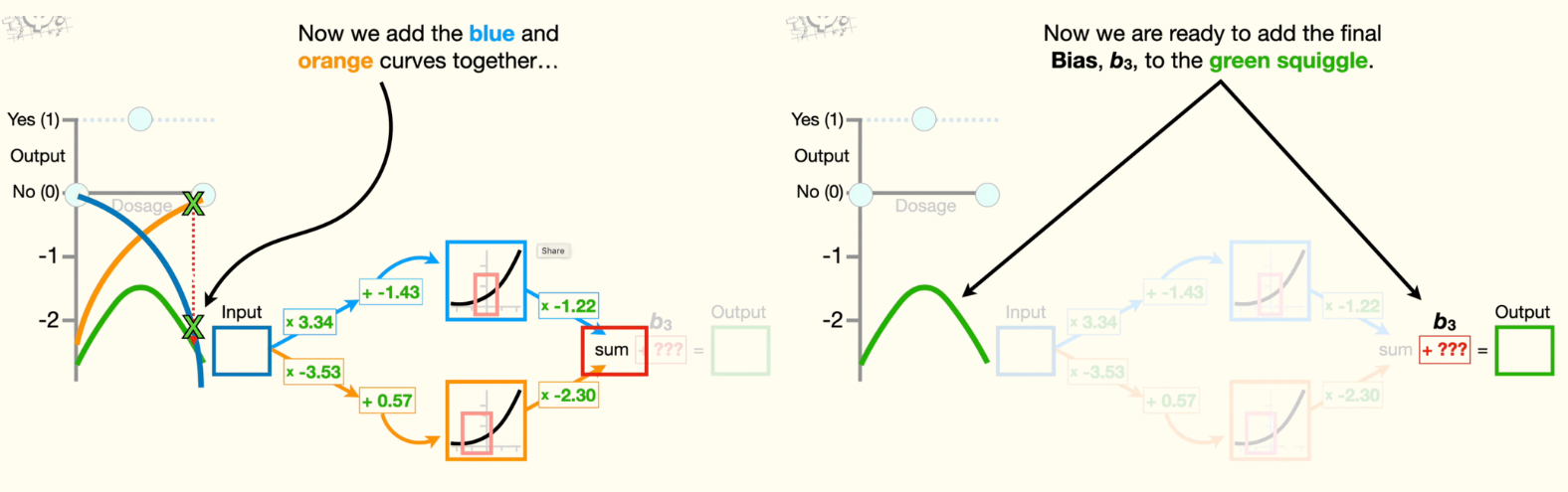
Now we add the blue and orange curves together to get this green squiggle. Now we are ready to add the final bias, b3, to the green squiggle. Because we don't yet know the optimal value for b3, we have to give it an initial value, and because bias terms are frequently initialized to 0, we will set b3 equal to 0. Now, adding zero to all of the y-axis coordinates on the green squiggle leaves it right where it is. However, that means the green squiggle is pretty far from the data that we observed.
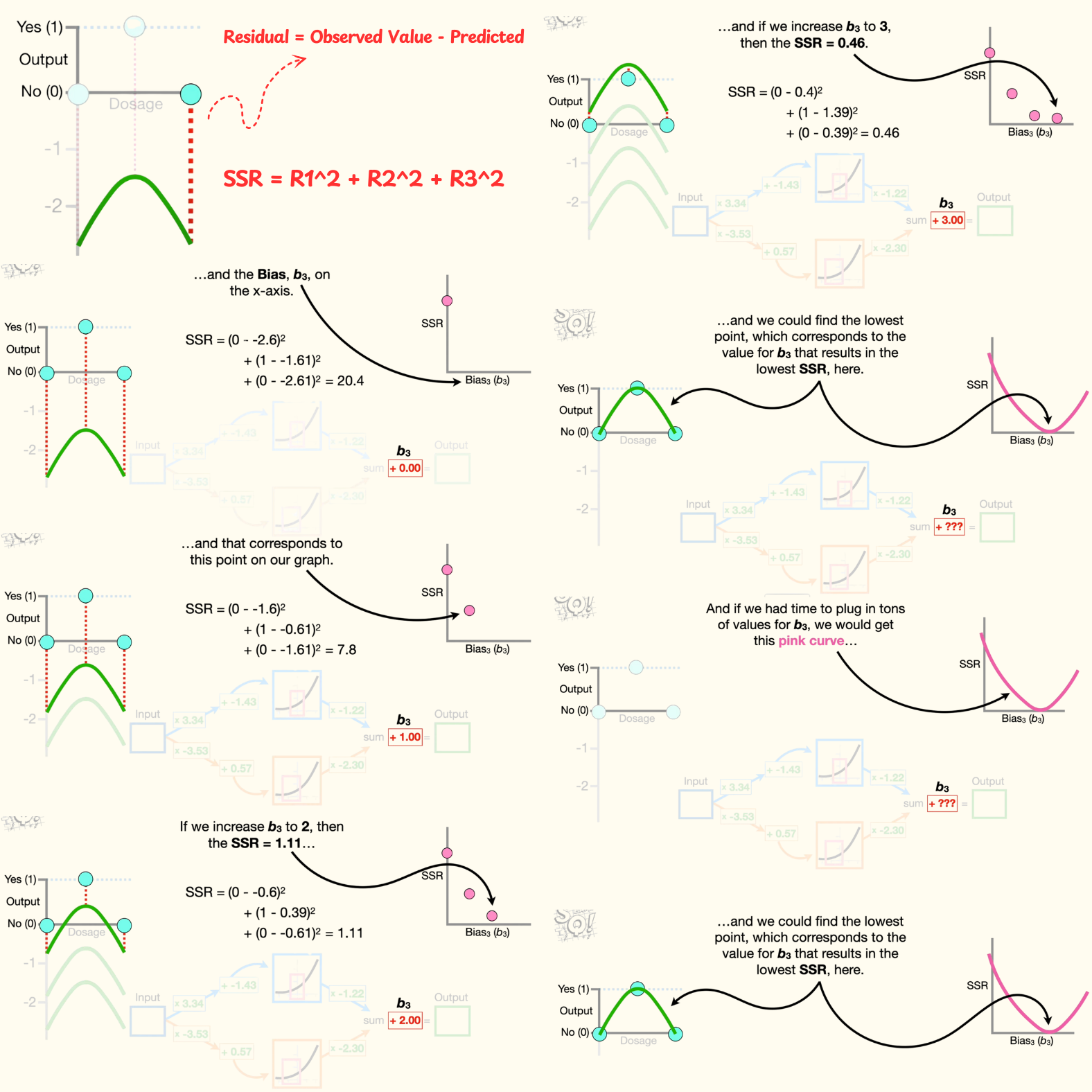
We can quantify how good the green squiggle fits the data by calculating the sum of the squared residuals. A residual is the difference between the observed and predicted values.
- First residual is the observed value, zero, minus the predicted value from the green squiggle, negative 2.6.
- Second residual is the observed value, one, minus the predicted value from the green squiggle, negative 1.61.
- Lastly, Third this residual is the observed value, 0, minus the predicted value from the green squiggle, negative 2.61.
- Now we square each residual and add them all together to get 20.4 for the sum of the squared residuals. So when b3 equals 0, the sum of the squared residuals equals 20.4. And that corresponds to this location on this graph that has the sum of the squared residuals on the y -axis and the bias, b3, on the x-axis.
- Now, if we increase b3 to 1, then we would add one to the y-axis coordinates on the green squiggle and shift the green squiggle up one. And we end up with shorter residuals. When we do the math, the sum of the squared residuals equals 7.8, and that corresponds to this point on our graph.
- If we increase b3 to 2, then the sum of the squared residuals equals 1.11. And if we increase b3 to 3, then the sum of the squared residuals equals 0.46.
- And if we had time to plug in tons of values for b3, we would get this pink curve, and we could find the lowest point, which corresponds to the value for b3 that results in the lowest sum of the squared residuals, here. However, instead of plugging in tons of values to find the lowest point in the pink curve, we use gradient descent to find it relatively quickly.
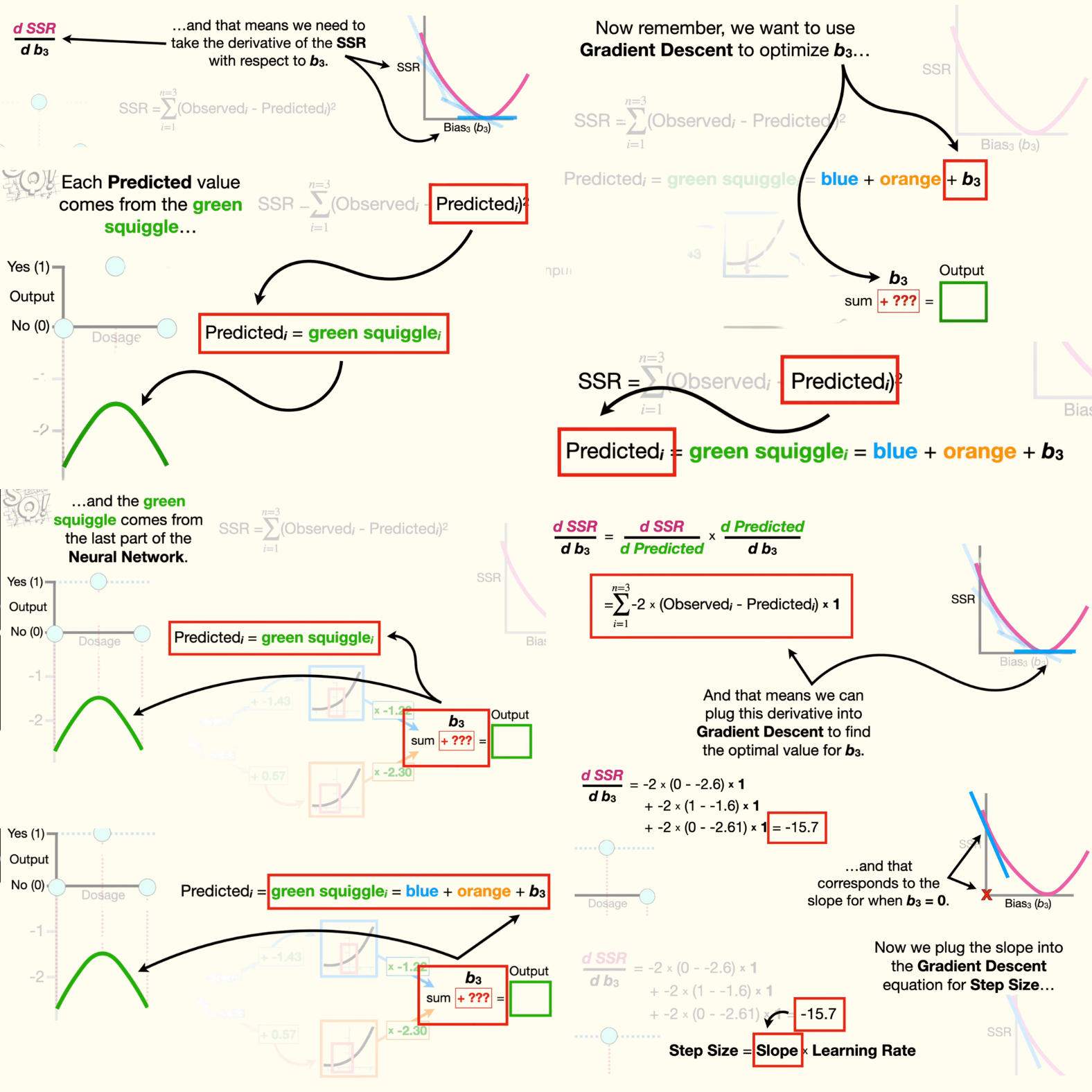
- And that means we need to find the derivative of the sum of the squared residuals with respect to b3. Now, remember the sum of the squared residuals equals the first residual squared, plus all of the other squared residuals.
- Now, because this equation takes up a lot of space, we can make it smaller by using summation notation. The greek symbol sigma tells us to sum things together, and 'i' is an index for the observed and predicted values that starts at one. And the index goes from one to the number of values, 'n', which in this case is set to 3. So, when 'i' equals one, we're talking about the first residual. When 'i' equals two, we're talking about the second residual And when 'i' equals three, we are talking about the third residual.
- Now let's talk a little bit more about the predicted values. Each predicted value comes from the green squiggle, and the green squiggle comes from the last part of the neural network. In other words, the green squiggle is the sum of the blue and orange curves, plus b3.
- Now remember, we want to use gradient descent to optimize b3, and that means we need to take the derivative of the sum of the squared residuals with respect to b3. And because the sum of the squared residuals are linked to b3 by the predicted values, we can use the chain rule to solve for the derivative of the sum of the squared residuals with respect to b3. The chain rule says that the derivative of the sum of the squared residuals with respect to b3 is the derivative of the sum of the squared residuals with respect to the predicted values, times the derivative of the predicted values with respect to b3.
- Now we can solve for the derivative of the sum of the squared residuals with respect to the predicted values by first substituting in the equation, and then use the chain rule to move the square to the front, and then we multiply that by the derivative of the stuff inside the parentheses with respect to the predicted values, negative one.
- Now we simplify by multiplying two by negative 1, and we have the derivative of the sum of the squared residuals with respect to the predicted values.
- Now let's solve for the second part: the derivative of the predicted values with respect to b3. We start by plugging in the equation for the predicted values. Remember, the blue and orange curves were created before we got to b3. So the derivative of the blue curve with respect to b3 is 0, because the blue curve is independent of b3. And the derivative of the orange curve with respect to b3 is also 0. Lastly, the derivative of b3, with respect to b3, is 1.
- Now we just add everything up, and the derivative of the predicted values with respect to b3, is one.
So we multiply the derivative of the sum of the squared residuals with respect to the predicted values by 1.
- Note: this times 1 part in the equation doesn't do anything, but I'm leaving it in to remind us that the derivative of the sum of the squared residuals with respect to b3 consists of two parts: the derivative of the sum of the squared residuals with respect to the predicted values, and the derivative of the predicted values with respect to b3. And at long last we have the derivative of the sum of the squared residuals with respect to b3.
- And that means we can plug this derivative into gradient descent to find the optimal value for b3. So let's move this equation up and show how we can use this equation with gradient descent.
- Anyway, first, we expand the summation. Then, we plug in the observed values and the values predicted by the green squiggle. Remember, we get the predicted values on the green squiggle by running the dosages through the neural network. Now, we just do the math and get negative 15.7. And that corresponds to the slope for when b3 equals zero.
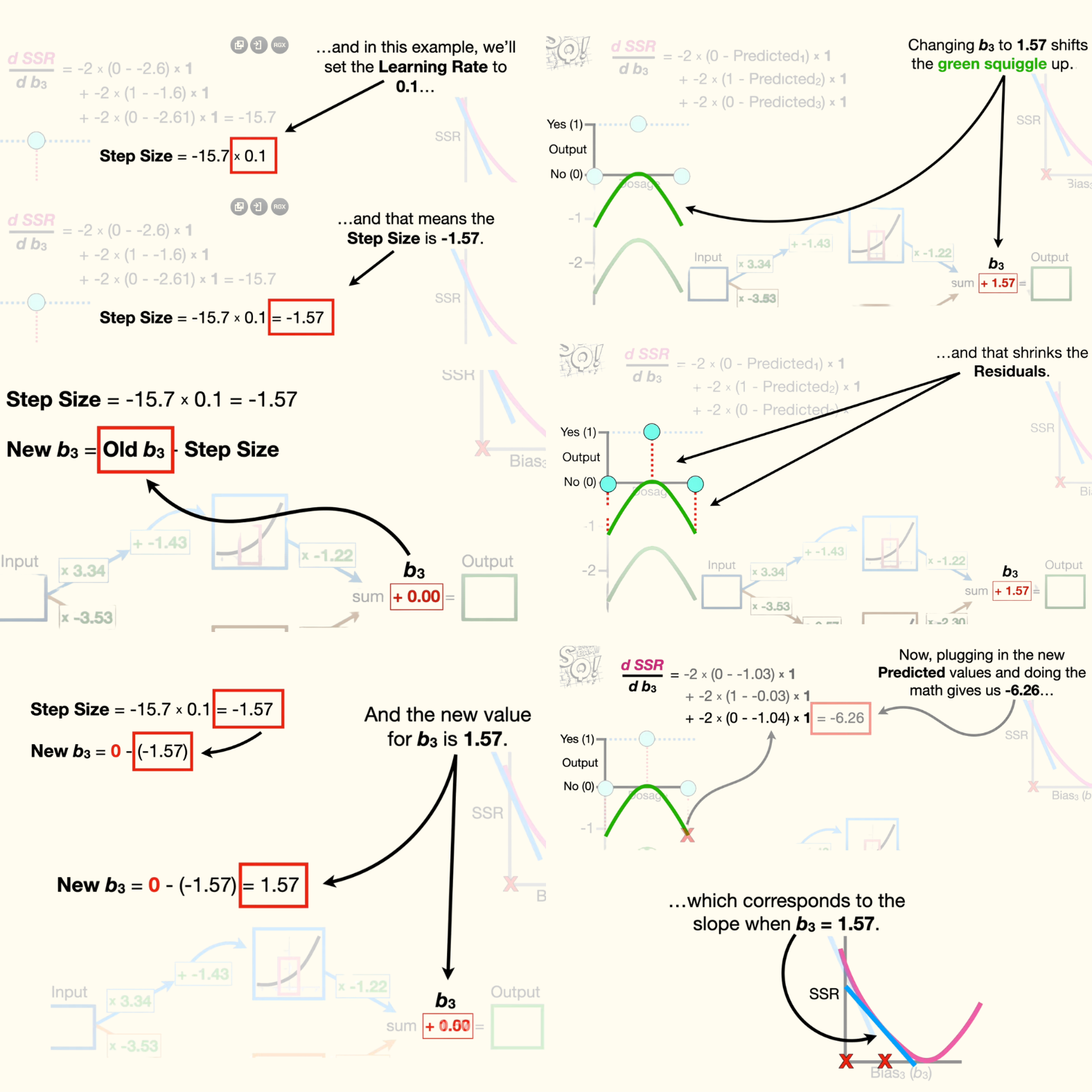
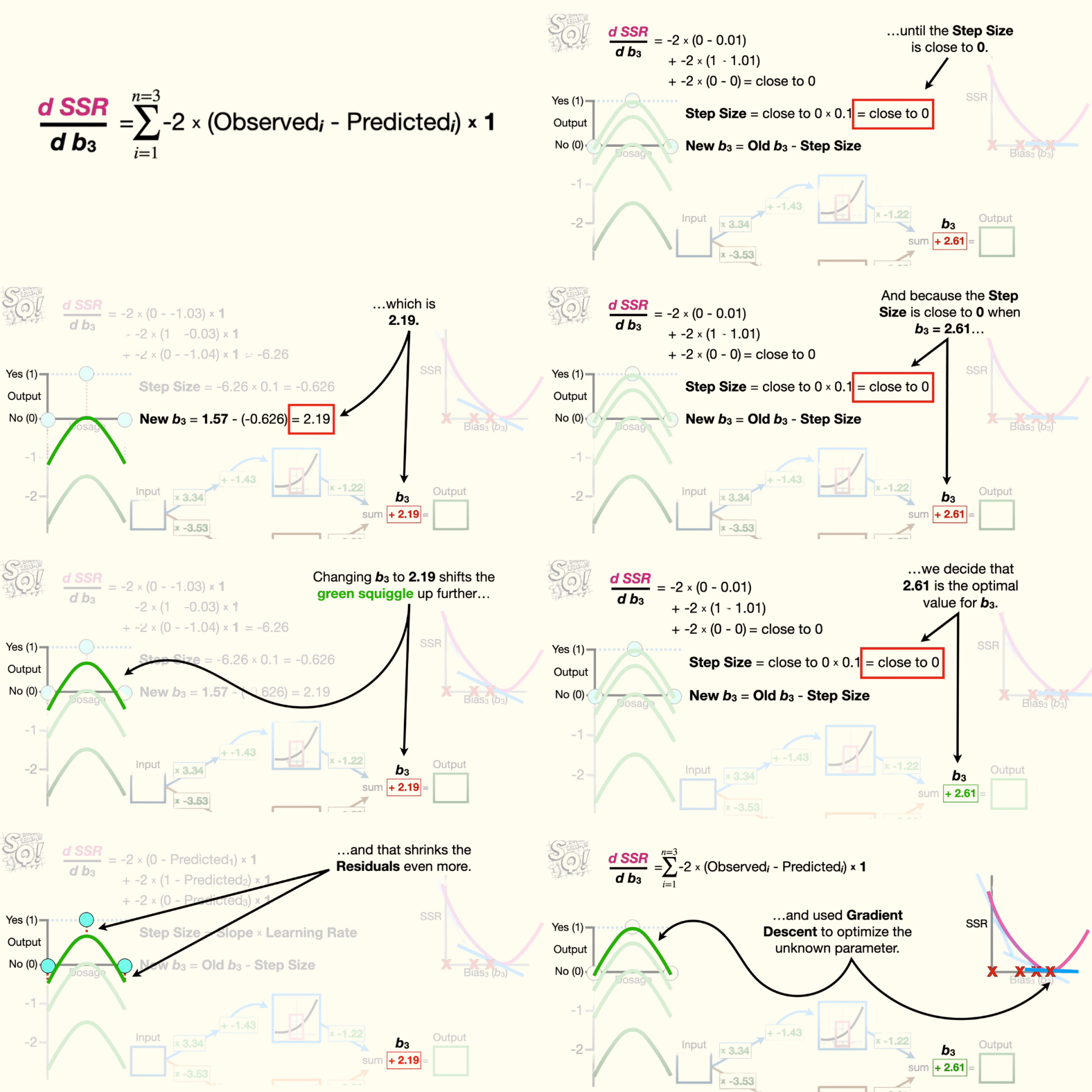
- Now we plug the slope into the gradient descent equation for step size, and, in this example, we'll set the learning rate to 0.1. And that means the step size is -1.57.
- Now we use the step size to calculate the new value for b3 by plugging in the current value for b3, zero, and the step size, -1.57. And the new value for b3 is 1.57. Changing b3 to 1.57 shifts the green squiggle up, and that shrinks the residuals.
- Now, plugging in the new predicted values and doing the math gives us -6.26, which corresponds to the slope when b3 equals 1.57. Then, we calculate the step size and the new value for b3, which is 2.19. Changing b3 to 2.19 shifts the green squiggle up further, and that shrinks the residuals even more.
- Now we just keep taking steps until the step size is close to zero. And because the step size is close to 0 when b3 equals 2.61, we decide that 2.61 is the optimal value for b3.
So, the main ideas for backpropagation are that, when a parameter is unknown, like b3, we use the chain rule to calculate the derivative of the sum of the squared residuals with respect to the unknown parameter, which in this case was b3. Then we initialize the unknown parameter with a number, and in this case we set b3 equal to zero, and used gradient descent to optimize the unknown parameter.
Optimizing All Parameters in Neural Networks
In a neural network, all weights and biases are optimized simultaneously during backpropagation, even though they might seem interconnected. Think of it like tuning a complex machine with many dials (parameters). When you adjust one dial (like a bias term), it affects how the other dials (weights and biases in earlier layers) need to be tuned to improve performance. Instead of fixing one parameter at a time, the network uses the chain rule to trace how every parameter contributes to the final error, starting from the output and working backward. Each weight and bias in hidden layers gets updated based on its role in propagating errors forward. Even after calculating an optimal value for a bias, the process continues iteratively—adjusting all parameters in small steps, over many cycles, until the network’s predictions align with the data. This ensures the entire system learns holistically, balancing all parts together rather than in isolation
{kind=link}