Lesson 1.3: Perceptron
MP Neuron
The MP Neuron (McCulloch-Pitts Neuron) is one of the earliest and simplest models of an artificial neuron, proposed by Warren McCulloch and Walter Pitts in 1943. It is a foundational concept in the field of artificial neural networks and serves as the basis for more advanced models like the Perceptron and modern deep learning architectures.The MP Neuron is historically significant as it was the first computational model of a biological neuron. It laid the foundation for the development of more advanced neural network models, such as the Perceptron and modern deep learning architectures. While it is not used in practice today, it remains an important concept for understanding the evolution of artificial neural networks.
+------------------------------+
X1 -----W1---> | |
| Threshold | -------> Output
X2 -----W2---> | |
+------------------------------+ Key Features of the MP Neuron
- Binary Inputs and Outputs:
- The MP Neuron takes binary inputs ( 0 or 1 )
- It produces a binary output ( 0 or 1 ).
- Weights and Threshold:
- Each input is associated with a weight which represents the importance of the input.
- The neuron has a threshold , which determines whether the neuron will "fire" (output 1) or not (output 0).
- Activation Function:
- The MP Neuron uses a step function as its activation function. The output is 1 if the weighted sum of inputs exceeds the threshold, and 0 otherwise.
- Activation Function introduce non lineariaty to the model. Example RelU, softmax.
- A step function is a mathematical function that outputs a binary value (e.g., 0 or 1) based on whether the input is greater than or less than a specified threshold.
- If sigmoid is used as the activation function, its interval is[0,1], when the output of a neuron is 1, it means that the neuron is activated, otherwise it is called unactivated.
- No Learning Mechanism:
- Unlike the Perceptron, the MP Neuron does not have a learning mechanism. The weights and threshold are fixed and must be manually set.
Perceptron
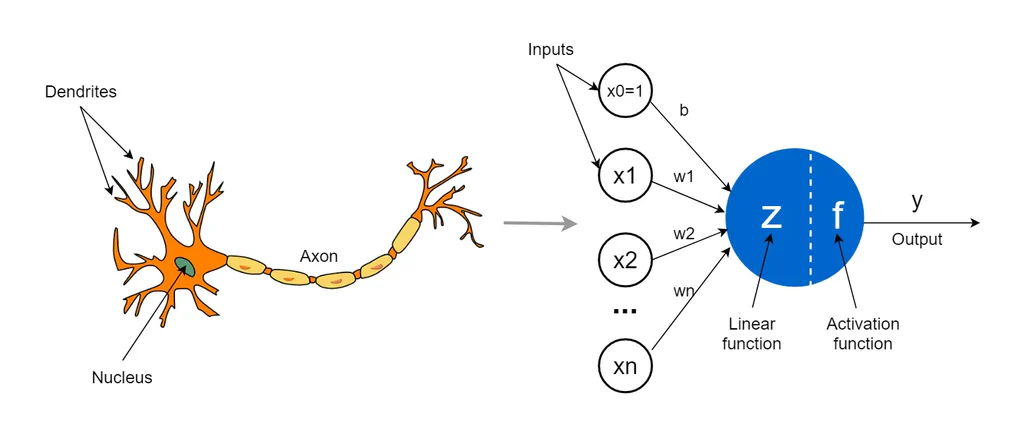
Perceptron is a type of neural network that performs binary classification that maps input features to an output decision, usually classifying data into one of two categories, such as 0 or 1. The perceptron is inspired by biological neurons. It takes multiple inputs, applies weights to them, sums them up, and passes the result through an activation function to produce an output.
+-----------------------------+ +------------------------------+
| MP NEURON | ----------> | PERCEPTRON |
| McCulloch-Pitts Neuron 1943 | | RosenBlatt's Perceptron 1958 |
+-----------------------------+ +------------------------------+ Perceptron consists of a single layer of input nodes that are fully connected to a layer of output nodes. It is particularly good at learning linearly separable patterns.
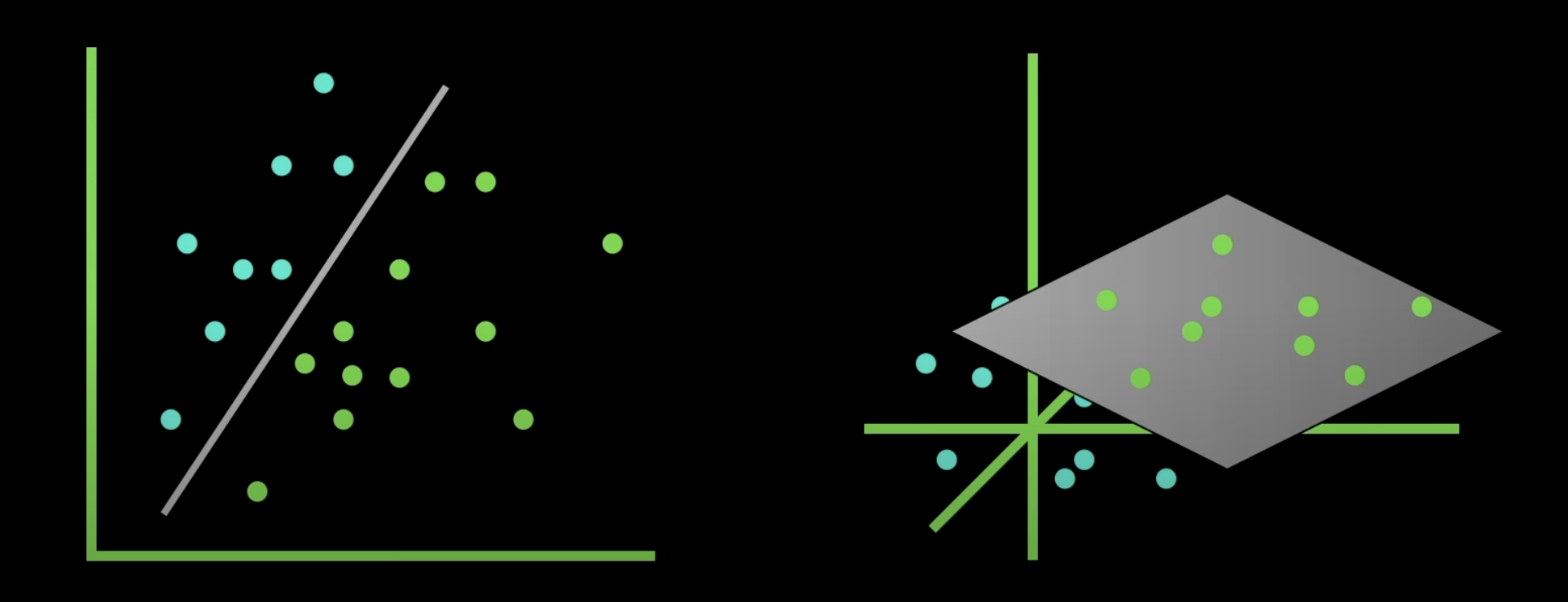
In the context of machine learning and neural networks, linearly separable patterns refer to data that can be divided into distinct classes using a straight line (in 2D), a plane (in 3D), or a hyperplane (in higher dimensions).
A hyperplane is a flat affine subspace of a higher-dimensional space. In simple terms, it is a boundary that separates a space into two parts. In two dimensions, a hyperplane is a line. In three dimensions, it is a plane. In higher dimensions, although it becomes difficult to visualize, the concept remains the same.
It utilizes a variation of artificial neurons called Threshold Logic Units (TLU), which were first introduced by McCulloch and Walter Pitts in the 1940s. This foundational model has played a crucial role in the development of more advanced neural networks and machine learning algorithms.
Mathematically, the output of a perceptron is:
where:
- : Inputs
- : Weights
- : Bias
- : Activation function (e.g., step function, sigmoid, ReLU)
A Perceptron is composed of key components that work together to process information and make predictions.
- Input Features: The perceptron takes multiple input features, each representing a characteristic of the input data.
- Weights: Each input feature is assigned a weight that determines its influence on the output. These weights are adjusted during training to find the optimal values.
- Summation Function: The perceptron calculates the weighted sum of its inputs, combining them with their respective weights.
- Activation Function: The weighted sum is passed through the Heaviside step function, comparing it to a threshold to produce a binary output (0 or 1). In basic perceptron the activation function is typically a step function.
- Output: The final output is determined by the activation function, often used for binary classification tasks.
- Bias: The bias term helps the perceptron make adjustments independent of the input, improving its flexibility in learning.
- Learning Algorithm: The perceptron adjusts its weights and bias using a learning algorithm, such as the Perceptron Learning Rule, to minimize prediction errors.
Types of Perceptron
- Single-Layer Perceptron
- A single-layer perceptron consists of only an input layer and an output layer.
- It can only learn linearly separable patterns because it uses a linear decision boundary (a hyperplane).
- It cannot solve problems where the relationship between inputs and outputs is non-linear (e.g., XOR problem).
- Multi-Layer Perceptron
- An MLP consists of:
- Input Layer: Receives the input features.
- Hidden Layers: One or more layers of neurons between the input and output layers.
- Output Layer: Produces the final output.
- The presence of hidden layers and non-linear activation functions enables MLPs to model complex, non-linear relationships.
- An MLP consists of:
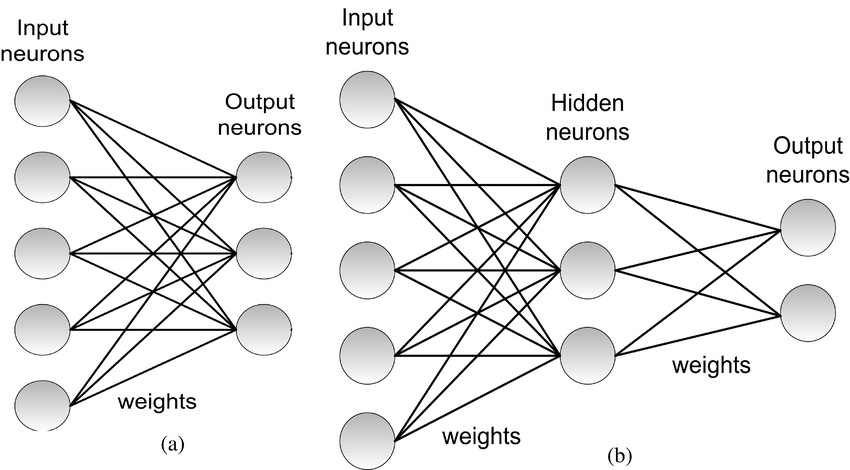
a. Single-Layer Perceptron , b. Multi-Layer Perceptron
How MLPs Handle Non-Linear Outputs
- Non-Linear Activation Functions:
- MLPs use non-linear activation functions (e.g., ReLU, sigmoid, tanh) in the hidden layers.
- These functions introduce non-linearity into the network, allowing it to learn complex patterns.
- Example: ReLU () is commonly used in hidden layers.
- Multiple Layers:
- Each hidden layer transforms the input data into a new representation.
- By stacking multiple layers, the network can learn hierarchical features, starting from simple patterns (e.g., edges in images) to complex patterns (e.g., objects in images).
- Universal Approximation Theorem:
- The theorem states that an MLP with at least one hidden layer and a non-linear activation function can approximate any continuous function to arbitrary precision, given enough neurons.
- This means MLPs can model any non-linear relationship between inputs and outputs.
Learning Algorithm in Perceptron
- Step 1: Initialize weight and bias.
- Step 2: Compute weighted sum, apply activation function, compute error.
- Step 3: Update weight and bias, if error using the learning rate.
- Step 4: Repeat until the model converges or stopping condition.
How does Perceptron work?
A weight is assigned to each input node of a perceptron, indicating the importance of that input in determining the output. The Perceptron’s output is calculated as a weighted sum of the inputs, which is then passed through an activation function to decide whether the Perceptron will fire.
The weighted sum is computed as:
The step function compares this weighted sum to a threshold. If the input is larger than the threshold value, the output is 1; otherwise, it’s 0. This is the most common activation function used in Perceptrons are represented by the Heaviside step function:
In a fully connected layer, also known as a dense layer, all neurons in one layer are connected to every neuron in the previous layer.The output of the fully connected layer is computed as:
where is the input , is the weight for each inputs neurons and is the bias and is the step function.
During training, the Perceptron’s weights are adjusted to minimize the difference between the predicted output and the actual output. This is achieved using supervised learning algorithms like the delta rule or the Perceptron learning rule. The weight update formula is:
Where:
- is the weight between the input and output neutron.
- is the input value.
- is the actual value and is the predicted value.
- is the learning rate controling how much the weights are adjusted.
This process enables the perceptron to learn from data and improve its prediction accuracy over time.