Clustered Tables
Clustered Index
Clustered indexes sort and store the data rows in the table or view based on their key values. These key values are the columns included in the index definition. There can be only one clustered index per table, because the data rows themselves can be stored in only one order.
The only time the data rows in a table are stored in sorted order is when the table contains a clustered index. When a table has a clustered index, the table is called a clustered table. If a table has no clustered index, its data rows are stored in an unordered structure called a heap.
In a clustered index structure, data is organized in a B-tree (Balanced Tree), which is highly efficient for searches, insertions, and deletions. Unlike a heap, where data is stored in an unstructured format, a clustered index arranges the table data itself in a sorted order based on the indexed column, allowing quick access to rows.
Example : MS SQL
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
Name NVARCHAR(50),
Age INT,
City NVARCHAR(50)
);Information about the indexes
This line means that the Customers table has a clustered index on the CustomerID column, which is also the primary key, making it both unique and sorted. This clustered index is stored in the PRIMARY filegroup. Because it’s a clustered index, the data rows in the table are physically ordered according to the CustomerID values, allowing for efficient retrieval of rows based on this key.
- Use
sp_helpindexwhen you need a quick, summary view of all indexes on a single table. - Use
sys.indexeswhen you need detailed information or want to filter or analyze index data across the database.
EXECUTE sp_helpindex Customers ;| index_name | index_description | index_keys |
|---|---|---|
| PK__Customer__A4AE64B802A9C4B4 | clustered, unique, primary key located on PRIMARY | CustomerID |
SELECT
i.name AS IndexName,
t.name AS TableName,
i.index_id,
i.type_desc AS IndexType,
i.is_unique,
i.is_primary_key
FROM
sys.indexes i
JOIN
sys.tables t ON i.object_id = t.object_id
WHERE
i.type = 1;| IndexName | IndexType | index_id | object_id |
|---|---|---|---|
| PK__Customer__A4AE64B802A9C4B4 | CLUSTERED | 1 | 311672158 |
- The output indicates that a clustered index exists on the CustomerID column in the Customers table. This index was not created explicitly by us; instead, it was automatically generated when we defined the primary key constraint on CustomerID
- By default, SQL Server creates a clustered index for the primary key, ensuring that the CustomerID values are unique and that the data is stored in a sorted order based on this column. This clustered index helps optimize data retrieval by ordering rows physically according to CustomerID.
Example
CREATE TABLE clustTable(
myid int IDENTITY(1,1) PRIMARY KEY CLUSTERED
,mychar VARCHAR(3500) DEFAULT REPLICATE('a',3500)
)
INSERT INTO dbo.clustTable DEFAULT VALUES;SELECT * FROM clustTable ; Result
| myid | mychar |
|---|---|
| 1 | aaaa... |
| 2 | aaaa... |
| 3 | aaaa... |
| 4 | aaaa... |
| 5 | aaaa... |
| 6 | aaaa... |
| 7 | aaaa... |
Messages 3:29:29 PMStarted executing query at Line 15 (7 rows affected) Table 'clustTable'. Scan count 1, logical reads 6, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. Total execution time: 00:00:00.011
DBCC ind(training_db, clustTable, 1)
go| PageFID | PagePID | IAMFID | IAMPID | ObjectID | IndexID | PartitionNumber | PartitionID | iam_chain_type | PageType | IndexLevel | NextPageFID | NextPagePID | PrevPageFID | PrevPagePID |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 305 | NULL | NULL | 901578250 | 1 | 1 | 72057594043695104 | In-row data | 10 | NULL | 0 | 0 | 0 | 0 |
| 1 | 312 | 1 | 305 | 901578250 | 1 | 1 | 72057594043695104 | In-row data | 1 | 0 | 1 | 314 | 0 | 0 |
| 1 | 313 | 1 | 305 | 901578250 | 1 | 1 | 72057594043695104 | In-row data | 2 | 1 | 0 | 0 | 0 | 0 |
| 1 | 314 | 1 | 305 | 901578250 | 1 | 1 | 72057594043695104 | In-row data | 1 | 0 | 1 | 315 | 1 | 312 |
| 1 | 315 | 1 | 305 | 901578250 | 1 | 1 | 72057594043695104 | In-row data | 1 | 0 | 1 | 316 | 1 | 314 |
| 1 | 316 | 1 | 305 | 901578250 | 1 | 1 | 72057594043695104 | In-row data | 1 | 0 | 0 | 0 | 1 | 315 |
The output of the DBCC IND command provides a detailed breakdown of the page-level information in SQL Server for the specified table (clustTable). This command is typically used to understand the structure and storage of data in SQL Server at the page level. Here’s what each of the columns in this output represents:
Column Breakdown:
-
PageFID (File ID): Indicates the file ID within the database where the page is located. In this case, it’s 1 for all rows, meaning all pages reside in the same file.
-
PagePID (Page ID): The page number within the specified file. This, combined with PageFID, uniquely identifies a page. For instance, page 305 would be located in file 1.
-
IAMFID (IAM File ID) and IAMPID (IAM Page ID): If a page is part of an IAM (Index Allocation Map) chain, these columns show the file ID and page ID of the IAM page that maps this page. In this case, only rows with PageType equal to 1 (data pages) have IAM mapping data (IAMFID = 1, IAMPID = 305).
-
ObjectID: The unique identifier for the table or index within the database. Here, 901578250 represents the clustTable object.
-
IndexID: Specifies the index ID on the object. IndexID = 1 denotes a clustered index (the primary key on myid in this case).
-
PartitionNumber: Indicates the partition number of the index. Here, 1 suggests all data is within a single partition.
-
PartitionID: The unique identifier for the partition within which these pages are stored.
-
iam_chain_type: Describes the storage type of the pages. In-row data signifies that data is stored within the rows on these pages.
-
PageType: Represents the type of page:
- 10: Indicates an index page, specifically the root page in the index (topmost level).
- 1: Represents a data page containing actual table data.
- IndexLevel: The level of the index where the page resides:
- 10: Root level in a clustered index (top of the index hierarchy).
- 2: Intermediate level (if applicable).
- 1: Leaf level (contains actual data rows).
-
NextPageFID and NextPagePID: Point to the next page in the same level of the index or data structure. For example, page 312 points to page 314 as its next page.
-
PrevPageFID and PrevPagePID: Point to the previous page in the same level. For example, page 314 points back to page 312.
Interpreting the Output:
- This output shows the structure of pages in the clustered index for clustTable, detailing the root page (with IndexLevel = 10), as well as intermediate and data pages (with IndexLevel = 1).
- Page 305 serves as a root page (or higher-level index page).
- Pages 312, 313, and 314 are data pages at the leaf level (IndexLevel = 1) containing the actual rows of data in clustTable.
Clustered Index Scan vs. Clustered Index Seek
Clustered Index Scan: Reads every row in the clustered index, typically resulting in a full table scan. Scans are generally less efficient than seeks, especially for large tables, as they may lead to higher I/O costs.
SELECT * FROM clustTable ; 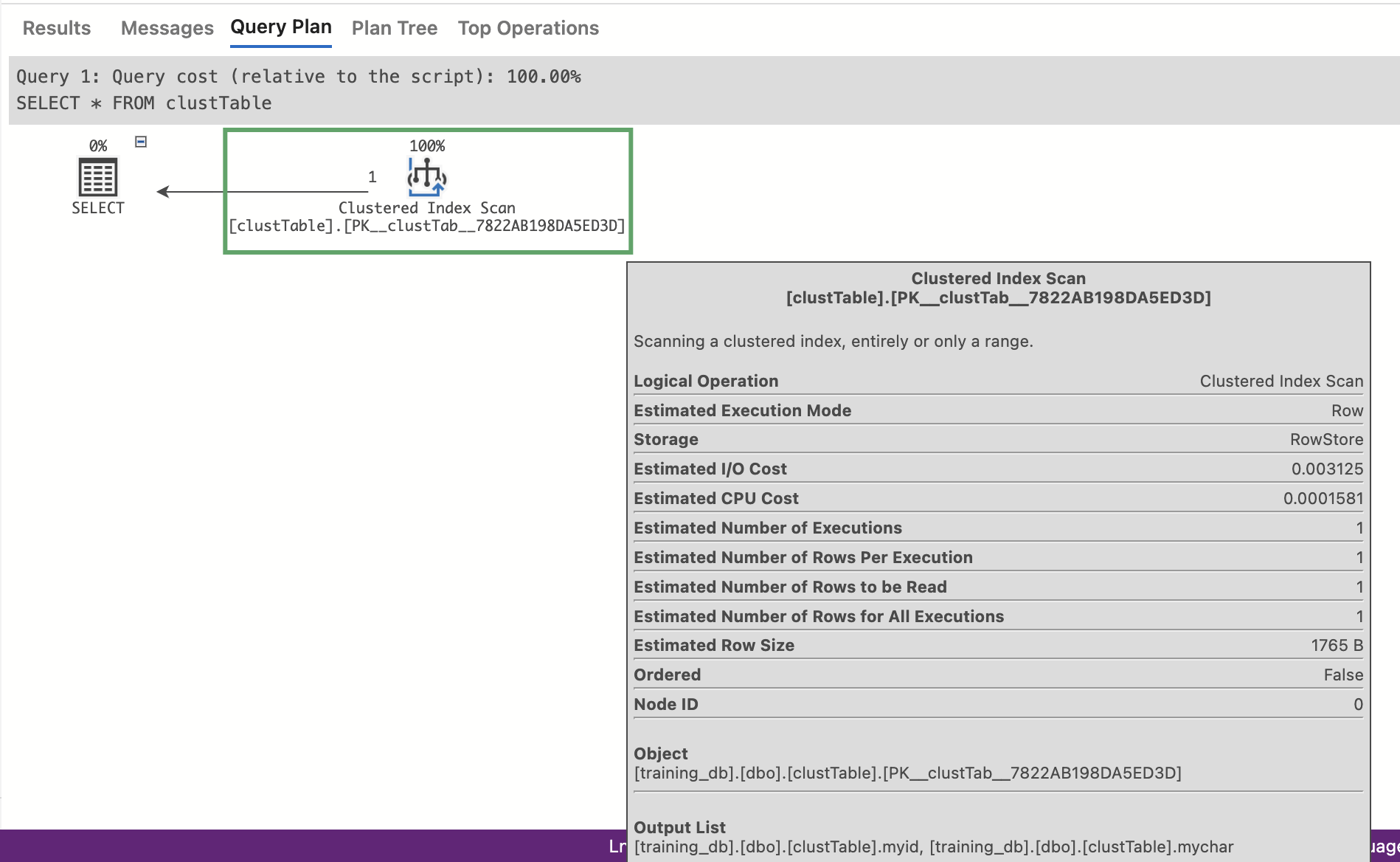
Fig: Query Plan - Clustered Index Scan
Clustered Index Seek: Used when SQL Server can directly locate specific rows based on indexed column values, making it much faster than a scan. For instance, if you had a query like SELECT * FROM clustTable WHERE myid = 5;, SQL Server would likely perform a Clustered Index Seek because it can directly access the page containing myid = 5 instead of reading the entire table.
SELECT * FROM clustTable where myid=5 ; 
Fig: Query Plan - Clustered Index Scan
Single Table Clustering
Single Table Clustering involves organizing the data of a single table based on the values of one or more columns, creating a clustered index on those columns. In a clustered table, the data rows themselves are physically ordered and stored according to the index key values of one or more columns. This type of clustering is particularly effective for queries that frequently search based on the clustered key values.
How Single Table Clustering Works:
- The clustered index is created on one or more columns of a single table.
- The data is stored on disk in an order that aligns with this index, so retrieval based on the indexed column(s) is fast.
- Each table can only have one clustered index because the data can be physically sorted in only one order.
- This approach reduces the number of I/O operations required when querying because the data is already sorted according to the clustered key, making range queries, joins, and sorting operations faster.
Example
CREATE TABLE People (
PersonID INT PRIMARY KEY IDENTITY(1,1),
FirstName NVARCHAR(50),
LastName NVARCHAR(50),
Age INT,
City NVARCHAR(50)
);
-- INSERT DATA IN PEOPLE TABLE
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
INSERT INTO People (FirstName, LastName, Age, City)
VALUES (
'First' + CAST(@i AS NVARCHAR(50)),
'Last' + CAST(@i AS NVARCHAR(50)),
FLOOR(RAND() * 100) + 1, -- Random age between 1 and 100
'City' + CAST((@i % 10) AS NVARCHAR(50)) -- Random cities (City0 to City9)
);
SET @i = @i + 1;
END;
-- IF ALREADY CREATED CLUSTERED INDEX, THEN REMOVE IT
ALTER TABLE People DROP CONSTRAINT PK__People__AA2FFB859D450124;
-- CREATE CLUSTERED INDEX
CREATE CLUSTERED INDEX IX_People_Age ON People (Age);EXECUTE sp_helpindex People ;| index_name | index_description | index_keys |
|---|---|---|
| IX_People_Age | clustered located on PRIMARY | Age |
DBCC ind(training_db, People, 1)
GO| PageFID | PagePID | IAMFID | IAMPID | ObjectID | IndexID | PartitionNumber | PartitionID | iam_chain_type | PageType | IndexLevel | NextPageFID | NextPagePID | PrevPageFID | PrevPagePID |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 308 | NULL | NULL | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 10 | NULL | 0 | 0 | 0 | 0 |
| 1 | 7872 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7880 | 0 | 0 |
| 1 | 7880 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7881 | 1 | 7872 |
| 1 | 7881 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7882 | 1 | 7880 |
| 1 | 7882 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7883 | 1 | 7881 |
| 1 | 7883 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7884 | 1 | 7882 |
| 1 | 7884 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7885 | 1 | 7883 |
| 1 | 7885 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7886 | 1 | 7884 |
| 1 | 7886 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7887 | 1 | 7885 |
| 1 | 7887 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 0 | 0 | 1 | 7886 |
| 1 | 7912 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 2 | 1 | 0 | 0 | 0 | 0 |
SELECT * FROM People
WHERE Age = 7 ; | PersonID | FirstName | LastName | Age | City |
|---|---|---|---|---|
| 62 | First62 | Last62 | 7 | City2 |
| 29 | First29 | Last29 | 7 | City9 |
| 58 | First58 | Last58 | 7 | City8 |
| 21 | First21 | Last21 | 7 | City1 |
| 229 | First229 | Last229 | 7 | City9 |
| 345 | First345 | Last345 | 7 | City5 |
| 302 | First302 | Last302 | 7 | City2 |
| 414 | First414 | Last414 | 7 | City4 |
| 431 | First431 | Last431 | 7 | City1 |
| 368 | First368 | Last368 | 7 | City8 |
| 572 | First572 | Last572 | 7 | City2 |
| 808 | First808 | Last808 | 7 | City8 |
| 650 | First650 | Last650 | 7 | City0 |
| 980 | First980 | Last980 | 7 | City0 |
| 889 | First889 | Last889 | 7 | City9 |
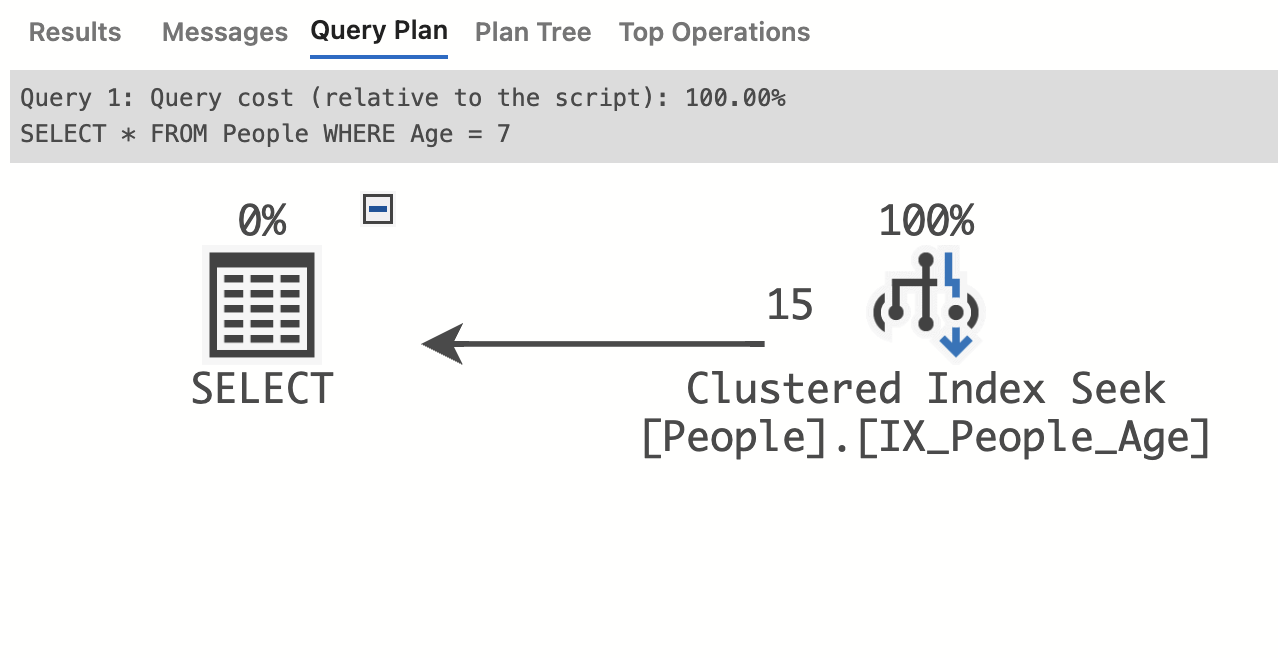
Query Plan - Single Table Clustering
DBCC ind(training_db, People, 1)
GO| PageFID | PagePID | IAMFID | IAMPID | ObjectID | IndexID | PartitionNumber | PartitionID | iam_chain_type | PageType | IndexLevel | NextPageFID | NextPagePID | PrevPageFID | PrevPagePID |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 308 | NULL | NULL | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 10 | NULL | 0 | 0 | 0 | 0 |
| 1 | 7872 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7880 | 0 | 0 |
| 1 | 7880 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7881 | 1 | 7872 |
| 1 | 7881 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7882 | 1 | 7880 |
| 1 | 7882 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7883 | 1 | 7881 |
| 1 | 7883 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7884 | 1 | 7882 |
| 1 | 7884 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7885 | 1 | 7883 |
| 1 | 7885 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7886 | 1 | 7884 |
| 1 | 7886 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 1 | 7887 | 1 | 7885 |
| 1 | 7887 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 1 | 0 | 0 | 0 | 1 | 7886 |
| 1 | 7912 | 1 | 308 | 997578592 | 1 | 1 | 72057594043957248 | In-row data | 2 | 1 | 0 | 0 | 0 | 0 |
Let's go through the key parts of the data you've posted to understand how SQL Server is organizing this index:
Key Columns in the Output
- PageFID and PagePID: File ID and Page ID of each page, uniquely identifying each page in the database.
- PageType: Type of the page, where:
- 10 generally represents an IAM (Index Allocation Map) page.
- 1 represents a data page at the leaf level (where actual data is stored).
- 2 typically represents an intermediate level page (pointer).
- IndexLevel: The level of the page within the B-tree. NULL for IAM pages, 1 for leaf-level pages, 2 for intermediate pages.
- NextPageFID and NextPagePID: Links to the next page at the same level. Used for scanning within the same level.
- PrevPageFID and PrevPagePID: Links to the previous page at the same level.
You can view the data stored in a specific leaf page in SQL Server, but it requires some low-level commands and careful handling. SQL Server provides the DBCC PAGE command to inspect the contents of a specific page in a database. This command allows you to look at the raw data stored on a page, including leaf pages.
DBCC PAGE (5, 1, 7887, 3);SELECT *, sys.fn_PhysLocFormatter(%%physloc%%) AS PageInfo
FROM People
WHERE Age IN (7, 75);| PersonID | FirstName | LastName | Age | City | PageInfo |
|---|---|---|---|---|---|
| 62 | First62 | Last62 | 7 | City2 | (1:7872:68) |
| 29 | First29 | Last29 | 7 | City9 | (1:7872:69) |
| 58 | First58 | Last58 | 7 | City8 | (1:7872:70) |
| 21 | First21 | Last21 | 7 | City1 | (1:7872:71) |
| 229 | First229 | Last229 | 7 | City9 | (1:7872:72) |
| 345 | First345 | Last345 | 7 | City5 | (1:7872:73) |
| 302 | First302 | Last302 | 7 | City2 | (1:7872:74) |
| 414 | First414 | Last414 | 7 | City4 | (1:7872:75) |
| 431 | First431 | Last431 | 7 | City1 | (1:7872:76) |
| 368 | First368 | Last368 | 7 | City8 | (1:7872:77) |
| 572 | First572 | Last572 | 7 | City2 | (1:7872:78) |
| 808 | First808 | Last808 | 7 | City8 | (1:7872:79) |
| 650 | First650 | Last650 | 7 | City0 | (1:7872:80) |
| 980 | First980 | Last980 | 7 | City0 | (1:7872:81) |
| 889 | First889 | Last889 | 7 | City9 | (1:7872:82) |
| 948 | First948 | Last948 | 75 | City8 | (1:7885:53) |
| 939 | First939 | Last939 | 75 | City9 | (1:7885:54) |
| 755 | First755 | Last755 | 75 | City5 | (1:7885:55) |
| 442 | First442 | Last442 | 75 | City2 | (1:7885:56) |
| 246 | First246 | Last246 | 75 | City6 | (1:7885:57) |
| 165 | First165 | Last165 | 75 | City5 | (1:7885:58) |
| 124 | First124 | Last124 | 75 | City4 | (1:7885:59) |
| 147 | First147 | Last147 | 75 | City7 | (1:7885:60) |
| 72 | First72 | Last72 | 75 | City2 | (1:7885:61) |
Multi-Level Clustering
Multi-Level Clustering (sometimes called clustered multi-level indexes or composite clustering) extends the concept of single table clustering to multiple tables or groups of data based on hierarchical or composite keys. This approach is beneficial when tables are frequently joined on common fields or when data is naturally hierarchical.
How Multi-Level Clustering Works:
- In multi-level clustering, tables that are frequently queried together (such as through joins) are stored together based on shared or related clustered keys.
- The primary clustering is done on the highest-level key, and additional clustering levels organize data within the clustered groups based on secondary key values.
- This approach minimizes I/O operations when accessing related data from multiple tables, as the data is co-located on disk in a way that matches common access patterns.
Example of Multi-Level Clustering:
Consider an e-commerce database with Customers and Orders tables:
- The Customers table could be clustered based on CustomerID.
- The Orders table could be clustered based on CustomerID and then OrderID.
Creating the table
- The Customers table has a primary key on CustomerID, which automatically creates a clustered index on that column.
- The Orders table has a primary key on OrderID, which automatically creates a clustered index on OrderID.
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY CLUSTERED,
LastName NVARCHAR(50),
FirstName NVARCHAR(50),
City NVARCHAR(50)
);
CREATE TABLE Orders (
OrderID INT PRIMARY KEY CLUSTERED,
CustomerID INT,
OrderDate DATETIME,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);Creating a Multi-Column Clustered Index on CustomerID and OrderDate
CREATE CLUSTERED INDEX IX_Orders_CustomerID_OrderDate
ON Orders (CustomerID, OrderDate);EXECUTE sp_helpindex Customers ;
EXECUTE sp_helpindex Orders ;| index_name | index_description | index_keys |
|---|---|---|
| PK__Customer__A4AE64B8703B9D53 | clustered, unique, primary key located on PRIMARY | CustomerID |
| index_name | index_description | index_keys |
|---|---|---|
| IX_Orders_CustomerID_OrderDate | clustered located on PRIMARY | CustomerID, OrderDate |
DBCC ind(training_db, Customers, 1)
GO| PageFID | PagePID | IAMFID | IAMPID | ObjectID | IndexID | PartitionNumber | PartitionID | iam_chain_type | PageType | IndexLevel | NextPageFID | NextPagePID | PrevPageFID | PrevPagePID |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 307 | NULL | NULL | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 10 | NULL | 0 | 0 | 0 | 0 |
| 1 | 7840 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7842 | 0 | 0 |
| 1 | 7841 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 2 | 1 | 0 | 0 | 0 | 0 |
| 1 | 7842 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7843 | 1 | 7840 |
| 1 | 7843 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7844 | 1 | 7842 |
| 1 | 7844 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7845 | 1 | 7843 |
| 1 | 7845 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7846 | 1 | 7844 |
| 1 | 7846 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7847 | 1 | 7845 |
| 1 | 7847 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7848 | 1 | 7846 |
| 1 | 7848 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7849 | 1 | 7847 |
| 1 | 7849 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 1 | 7850 | 1 | 7848 |
| 1 | 7850 | 1 | 307 | 1621580815 | 1 | 1 | 72057594045857792 | In-row data | 1 | 0 | 0 | 0 | 1 | 7849 |
-- Insert 1000 dummy records into Customers
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
INSERT INTO Customers (CustomerID, LastName, FirstName, City)
VALUES (@i, CONCAT('LastName', @i), CONCAT('FirstName', @i), 'City' + CAST((@i % 10) AS NVARCHAR(10)));
SET @i = @i + 1;
END;
-- Insert 1000 dummy records into the Orders table
DECLARE @Counter INT = 1;
WHILE @Counter <= 1000
BEGIN
INSERT INTO Orders (OrderID, CustomerID, OrderDate)
VALUES (
@Counter, -- OrderID is simply the counter
(RAND() * 1000) + 1, -- Random CustomerID between 1 and 1000
DATEADD(DAY, (RAND() * 365), '2023-01-01') -- Random OrderDate in 2023
);
SET @Counter = @Counter + 1;
END;Now that we have created the multi-column clustered index on the Orders table, let's run some queries to see how the multi-column clustered index works.
Query 1: Find all orders for a specific customer and a range of order dates
When you run a SELECT query filtering on CustomerID and OrderDate, the database engine will use the multi-column clustered index to efficiently retrieve the data.
-- Query 1: Find all orders for a specific customer and a range of order dates
SELECT o.OrderID, o.CustomerID, o.OrderDate, c.LastName, c.FirstName
FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
WHERE o.CustomerID = 500
AND o.OrderDate BETWEEN '2023-01-01' AND '2023-12-31'
ORDER BY o.OrderDate;| OrderID | CustomerID | OrderDate | LastName | FirstName |
|---|---|---|---|---|
| 529 | 500 | 2023-03-02 00:00:00.000 | LastName500 | FirstName500 |
| 441 | 500 | 2023-08-22 00:00:00.000 | LastName500 | FirstName500 |
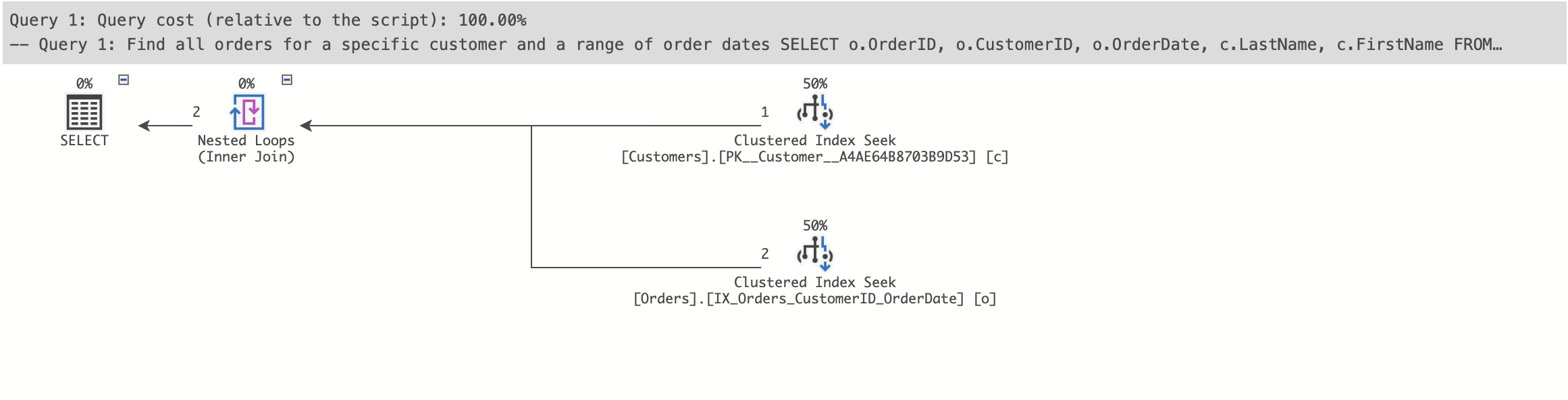
Query Plan : Query 1 Multi-table clustering
Reference : https://www.youtube.com/watch?v=FJTk310B4A8