Document DBs
MapReduce is a programming model used for processing and generating large datasets. The concept was originally developed by Google to handle vast amounts of data across distributed computing systems. The model is designed to process data in parallel across many computers, ensuring scalability, fault tolerance, and performance.
In MapReduce, the computation is divided into two main functions:
- Map Function: It processes the input data and produces intermediate key-value pairs.
- Reduce Function: It processes the intermediate key-value pairs generated by the map function and aggregates them to produce the final output.
MapReduce Functions
Key Concepts of MapReduce
-
Input and Output
- Input: The input to a MapReduce job is a collection of key/value pairs. These pairs represent data that needs to be processed. In the context of big data, this could be millions of rows in a dataset, or it could be documents, logs, etc.
- Output: The output is also a collection of key/value pairs that represent the processed data after the map and reduce functions are applied.
-
Map Function
- The map function is applied to each input key/value pair. It processes the data and emits intermediate key/value pairs.
- Input: A single key/value pair.
- Output: A list of key/value pairs that are the "intermediate" results of processing the input.
- Map Function Steps:
- Each input key-value pair is processed by the map function.
- The map function outputs intermediate key-value pairs, often in a form that's easier for the reduce function to process.
-
Reduce Function
- The reduce function takes the intermediate key/value pairs generated by the map function and processes them to produce the final output.
- Input: A key and a list of associated intermediate values.
- Output: A merged list of values, which are usually the results of some kind of aggregation, transformation, or filtering.
- Reduce Function Steps:
- Group the intermediate values by the key.
- Perform an operation (like summing, averaging, or concatenating) on the grouped values.
- Emit the final output key-value pair.
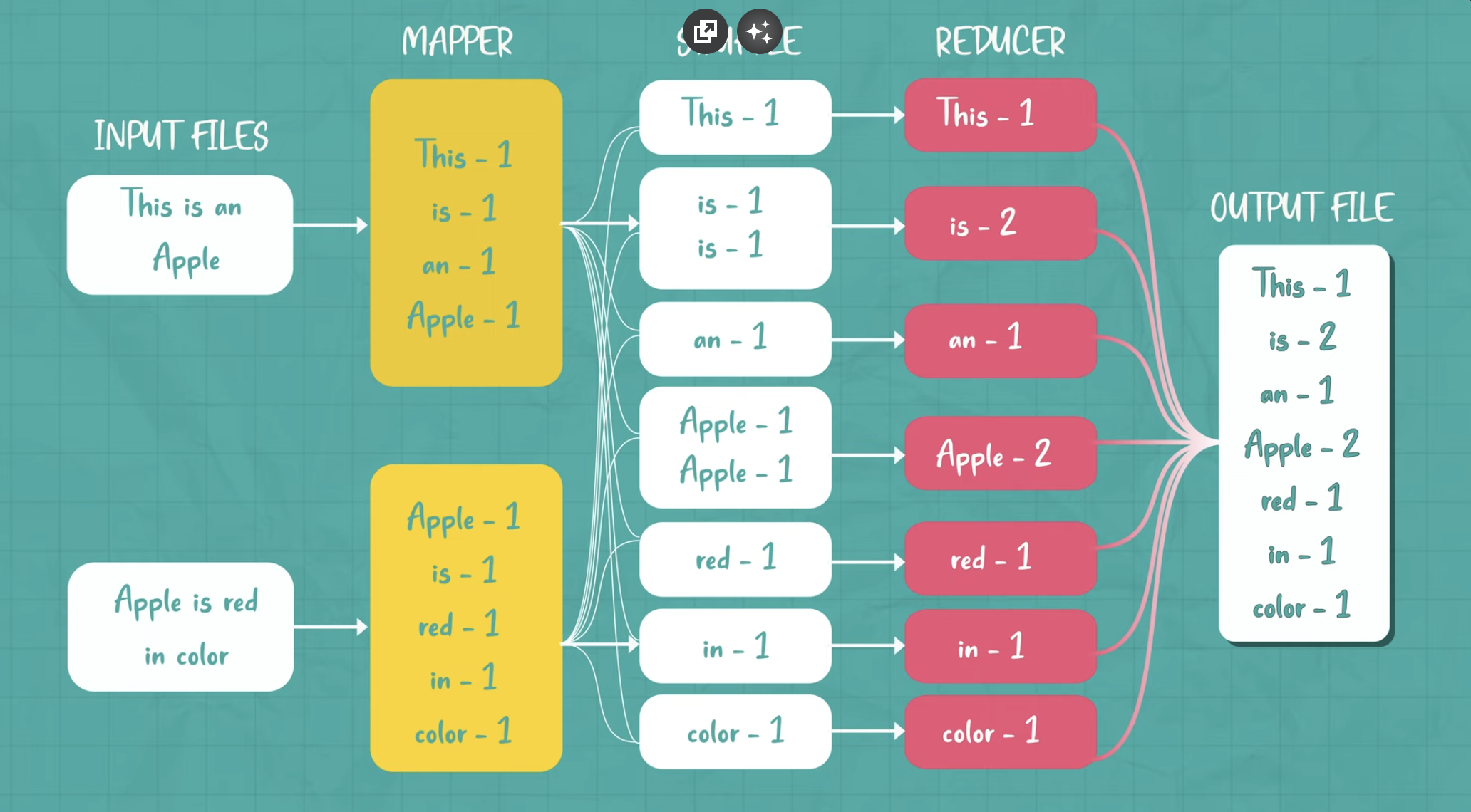
MapReduce Example: Word Count
Let’s walk through a specific example: counting word occurrences in a collection of documents. The goal is to count how many times each word appears across all documents.
- Step 1: Input
- The input consists of a collection of documents, each identified by a key (e.g., the document name) and a value (e.g., the content of the document).
- Example input:
("doc1", "hello world hello")
("doc2", "hello")- Step 2: The Map Function
- The map function processes each document. It reads the contents of the document (the input_value), splits it into individual words, and emits an intermediate key-value pair for each word in the document. The key is the word, and the value is "1", representing one occurrence of the word.
map(String input_key, String input_value):
// input_key: document name (e.g., "doc1")
// input_value: document content (e.g., "hello world hello")
for each word w in input_value:
EmitIntermediate(w, "1");Intermediate Output for "doc1":
("hello", 1)
("world", 1)
("hello", 1)Intermediate Output for "doc2":
("hello", 1)So, the map function processes the input data and generates intermediate results.
- Step 3: Shuffling and Grouping After the map phase, the system performs a shuffle and sort operation. This step groups all the intermediate values by their key. In our case, all occurrences of the word "hello" will be grouped together, and all occurrences of "world" will be grouped together.
Grouped intermediate data:
("hello", [1, 1, 1])
("world", [1])- Step 4: The Reduce Function The reduce function receives each group of intermediate key-value pairs. It processes the list of values (in this case, the word counts) for each key and aggregates them (by summing the counts).
Reduce Function Code:
reduce(String output_key, Iterator intermediate_values):
// output_key: a word (e.g., "hello")
// intermediate_values: list of counts (e.g., ["1", "1", "1"])
int result = 0;
for each v in intermediate_values:
result += ParseInt(v); // Summing the counts
Emit(AsString(result)); // Emit the final count for the wordFor "hello":
- intermediate_values = [1, 1, 1]
- The reduce function sums the values: 1 + 1 + 1 = 3
- The result is ("hello", 3)
For "world":
- intermediate_values = [1]
- The reduce function sums the values: 1
- The result is ("world", 1)
- Step 5: Final Output The final output is the result of the aggregation performed by the reduce function. After processing all the intermediate results, the output is:
("hello", 3)
("world", 1)This output indicates that the word "hello" appears 3 times across the documents and the word "world" appears once.
Advantages of MapReduce
- Parallelism: The map and reduce tasks can be run in parallel across multiple machines in a cluster, making MapReduce highly scalable.
- Fault Tolerance: If a task fails, it can be retried on another machine without affecting the overall process.
- Simplicity: Developers only need to write the map and reduce functions, while the framework handles distribution, fault tolerance, and aggregation.
Use Cases
MapReduce is widely used in big data processing tasks, such as:
- Log processing (counting events, analyzing logs)
- Data analytics (aggregating large datasets)
- Machine learning (training models on large datasets)
- Search indexing (building inverted indices for search engines)
While it was first popularized by Google, frameworks like Apache Hadoop and Apache Spark now offer MapReduce-style programming models for distributed data processing across large clusters.