TAPAS Weakly Supervised Table Parsing via Pre-training
View PDF: https://arxiv.org/abs/2004.02349
Example Summarization

Example Type
-
Cell Selection - This task involves directly selecting the correct cell(s) in the table to answer a question. The answer exists explicitly in the table and can be retrieved without additional computation or logic.
- Example:
- Question: Which wrestler had the most number of reigns?
- To answer this, you look at the "Number of Reigns" column, find the highest value (8), and select the corresponding wrestler.
- Answer: Ric Flair (as the wrestler with the most reigns).
- Why it's Cell Selection: The answer (Ric Flair) is explicitly present in the table and is retrieved by locating the appropriate cell based on the question.
- Example:
-
Scalar Answer - This task involves computing a numerical value that is not directly available in the table. The model must perform operations like averaging, summing, or subtraction to derive the answer.
- Question What is the average time as a champion for the top two wrestlers?
- Look at the "Combined Days as Champion" column for the top two wrestlers (ranked 1 and 2):
- Wrestler ranked 1: 1500 days.
- Wrestler ranked 2: 1000 days.
- Compute the average: AVG(3749,3103)=3426
- Look at the "Combined Days as Champion" column for the top two wrestlers (ranked 1 and 2):
- Why it's Scalar Answer: The answer is derived through computation (average), not directly available in any cell of the table.
- Question What is the average time as a champion for the top two wrestlers?
-
Ambiguous Answer - The numerical value of the answer is present in the table, but selecting that value directly from a cell would not provide the correct answer because the context or semantics differ.
- Ambiguous answers often involve an operation like counting, summing, or filtering rows/columns based on criteria provided in the question.
- Example: If the question asks, "How many wrestlers have only one reign?", and the table has a column for "Number of Reigns" with some rows showing the value 1, the answer is 2 (since there are two such rows), not just selecting a cell containing 1.
Key Challenges in Table QA
Different Question Types: Questions require distinct forms of reasoning, such as:
- Direct selection from the table.
- Performing computations.
- Resolving ambiguity in meaning or intent.
- Multiple Modes of Reasoning: The model must identify what kind of operation (selection, computation, or reasoning) is needed for each question.
Proposed Model Overview
To address these challenges, the TAPAS model (presented in the paper) introduces a pipeline with distinct components:
- Mode Selection
The model must decide whether the task requires:
- Cell Selection: Directly picking cells from the table.
- Computation: Performing a calculation such as sum, average, or count.
- What computation to perform (e.g., sum, average, count).
- What cells or rows to operate on (e.g., selecting "Combined Days as Champion" for the average calculation).
- Reasoning: Resolving ambiguity or applying logical operations.
Traditional Approach Workflow:
Question → Logical Form → Query
- Step 1: Question → Logical Form
- The first step is to convert the natural language question into a logical form.
- A logical form is a structured representation of the meaning of the question, often in a formal query language.
- Example** : "Which wrestler had the most number of reigns?" **could be converted into a logical form that looks something like this:
SELECT wrestler_name FROM table WHERE reigns = MAX(reigns)
- Step 2: Logical Form → Query
- The logical form is then converted into a query that can be executed against the data (usually in SQL or a similar query language).
- The system generates a query based on the logical form. In our case, the query could look like this:
SELECT Name FROM table WHERE Reigns = (SELECT MAX(Reigns) FROM table)
- Step 3: Execution of the Query
- The query is then executed against the table data, and the result is returned.
Challenges with the Traditional Approach:
- Dependence on Logical Form:
- The traditional approach relies on accurately converting the natural language question into a logical form. This requires a sophisticated understanding of syntax and semantics, and it may not handle ambiguity or rephrasing of the question very well.
- Manual Mapping:
- The logical form often involves manual mapping to predefined keywords or structures, which means the system might fail if the question is phrased differently or if the table's column names change.
- Keyword Sensitivity:
- The system is keyword-driven. If the question contains words that don’t exactly match the keywords expected by the system, it might fail to generate the correct logical form or query.
- Example: If the question was "Who holds the highest number of reigns?" instead of "Which wrestler had the most number of reigns?", the system may struggle because it might expect "most" rather than "highest."
- Data Requirements:
- A large amount of annotated data is needed to train the model to generate correct logical forms for a wide variety of questions. This is expensive and time-consuming to obtain.
Comparison to TAPAS:
In contrast to the traditional approach, TAPAS directly processes both the natural language question and the table in a single sequence, using token embeddings and special embeddings (like column, row, and rank embeddings) to encode the relationships between the question and the table. This approach avoids the need for explicit logical forms and instead relies on the model's ability to directly reason over the table data, making it more flexible and efficient.
TAPAS MODEL
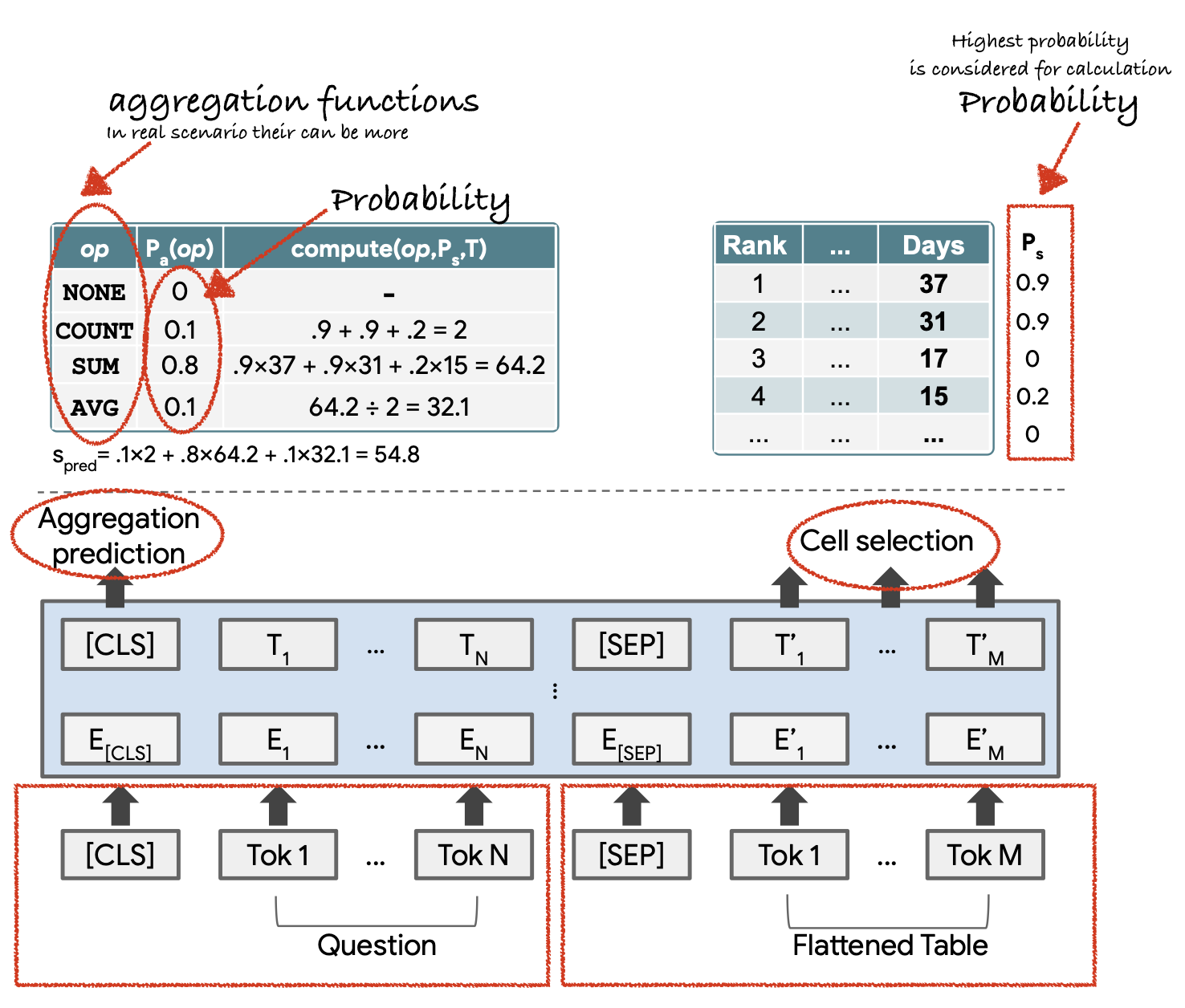
TAPAS (Table Parsing) is a model designed to perform question answering over tables using BERT as its backbone. Figure 1 in the TAPAS paper provides a high-level view of how the model processes a question and a table together to generate the correct answer. Here's a breakdown of the process shown in Figure 1:
BERT Archietecture
BERT (Bidirectional Encoder Representations from Transformers) is a transformer-based architecture that considers the context of each token both before and after it. This is achieved through bidirectional attention.
For example :
- In the sentence:
The cat sat on the mat. - When processing the word
sat, BERT considers:- Before:
The cat - After:
on the matThis bidirectional approach allows BERT to understand the full context of each token, rather than just a partial view based on surrounding tokens. This results in better understanding of the meaning of words in context.
- Before:
Natural Language Question and Input Table Flattened as Token Embeddings:
The input to the TAPAS model consists of:
- Natural Language Question
- Structured Table
Both the question and the table are flattened into a single sequence of tokens. Each token from both the question and table is represented by a token embedding, and special embeddings are added to indicate their role (question or table) and their position within the structure of the table.
Flattening of Table and Question:
- The question (e.g., "What is the sum of the top two days as champions?") is tokenized into words/subwords.
- The table is also flattened and tokenized, where each cell, column header, and row header are treated as tokens in the sequence.
Table:
| Name | Reigns | Days as Champion |
|---|---|---|
| Ric Flair | 8 | 3749 |
| Lou Thesz | 3 | 3103 |
Flattened into tokens: "What is the sum of the top two days as champions?" [SEP] "Name Reigns Days as Champion Ric Flair 8 3749 Lou Thesz 3 3103"
Embedding Layers:
Once the table and question are flattened, the model processes the sequence using various embedding layers:
-
Token Embeddings:
- Each word or subword is converted into a dense vector representation using a pre-trained embedding table.
-
Position Embeddings:
- These embeddings capture the position of each token in the sequence. Since transformers are not inherently aware of sequence order, position embeddings help the model understand the order of tokens in the input.
-
Segment Embeddings:
- These embeddings differentiate between the question and the table.
- Tokens from the question get Segment 0 embeddings.
- Tokens from the table get Segment 1 embeddings.
-
Column and Row Embeddings:
- Column embeddings mark which column each token belongs to in the table (e.g., "Name" column, "Reigns" column).
- Row embeddings mark the row each token belongs to in the table (e.g., Row 1, Row 2).
- These embeddings help the model understand the structure of the table.
-
Rank Embeddings:
- These embeddings indicate the ranking of numerical values within a column.
- For example, in the "Days as Champion" column, the wrestler with the most days as champion is ranked first, the next highest ranked second, and so on.
Example Questions
Q : "How many wrestlers held the title for more than 1500 days?"
To answer this, TAPAS must:
- Understand the operation (e.g., count).
- Select relevant cells (i.e., cells in the "Days as Champion" column greater than 1500).
- Perform the computation (count those rows).
Step 1: Predict the Aggregation Type
The model needs to decide which operation to use for this question. It assigns probabilities to different possible aggregation types based on the context of the question:
| Aggregation Type | Probability |
|---|---|
| COUNT | 0.85 |
| SUM | 0.10 |
| AVERAGE | 0.03 |
| NONE (Select) | 0.02 |
Here, the COUNT operation has the highest probability (0.85), so the model selects COUNT as the aggregation type.
Step 2: Predict Relevant Cells
Next, the model assigns probabilities to each cell in the "Days as Champion" column, based on whether it is relevant to the question ("more than 1500 days"):
| Row Cell | Value | Probability (Relevant) |
|---|---|---|
| Ric Flair | 3749 | 0.95 |
| Harley Race | 1799 | 0.90 |
| Dory Funk Jr. | 1563 | 0.85 |
| Dan Severn | 1559 | 0.80 |
| Gene Kiniski | 1131 | 0.20 |
-
Explanation of Probabilities
- Gene Kiniski (1131) has a much lower cell value (less than 1500) and is assigned a low probability (0.20). This indicates that the model is confident that this row is not relevant.
- All other rows (Ric Flair, Lou Thesz, Harley Race, Dory Funk Jr., Dan Severn) meet the condition (>1500) and are assigned higher probabilities.
-
Which Rows Are Selected?
- TAPAS uses a probability threshold (e.g., 0.5) to decide which rows are relevant.
- Rows with probabilities above 0.5 are included in the count. In this case:
- Ric Flair, Lou Thesz, Harley Race, Dory Funk Jr., and Dan Severn are selected.
- Gene Kiniski is excluded because his probability (0.20) is below the threshold.
-
Final Output
- The model includes the relevant rows (values > 1500), excluding Gene Kiniski.
- Final count: 5 wrestlers held the title for more than 1500 days.
Why This Is Important
This example shows how probabilities help handle:
- Ambiguous Cases: If Gene Kiniski had a value closer to 1500 (e.g., 1499), the model might assign him a probability closer to 0.5, making the decision less binary.
- Error Resilience: TAPAS doesn't just rely on hard thresholds (e.g., value > 1500); it uses probabilities to weigh the importance of rows, ensuring better robustness.
Probability in Ambiguous Questions
Now, let’s tweak the question to show ambiguity and how probabilities handle it.
Question: "What is the average number of days held by wrestlers with more than 1500 days?"
| Aggregation Type | Probability |
|---|---|
| AVERAGE | 0.60 |
| SUM | 0.30 |
| COUNT | 0.08 |
| NONE (Select) | 0.02 |
Here, the AVERAGE operation has the highest probability (0.60), but there’s some uncertainty (SUM: 0.30). The model still selects AVERAGE because it has the highest confidence, though the model indicates it’s less certain than the first example.
Limitations of TAPAS Models
- Single Table Input:
- TAPAS models are designed to handle a single table at a time. If the task involves querying or aggregating data across multiple tables, it cannot directly handle such operations. This limitation makes it unsuitable for tasks that require complex relational database queries.
- Memory Constraints:
- The size of the table is limited by the memory constraints of the model. Very large tables may exceed the model's capacity, making it challenging to handle datasets that cannot be reduced or summarized into smaller tables.
- Limited Expressivity:
- TAPAS can perform simple aggregations (e.g., counting, summing, or filtering rows). However, its expressivity is limited when it comes to:
- Performing nested operations (e.g., aggregating results of one query before applying a second aggregation).
- Handling complex queries that require multiple layers of reasoning or multi-step computations.
- TAPAS can perform simple aggregations (e.g., counting, summing, or filtering rows). However, its expressivity is limited when it comes to:
- Accuracy on Complex Structures:
- For tables that require multiple aggregations or logical reasoning across columns, TAPAS might struggle, leading to lower accuracy in such scenarios. For example:
- Queries that require grouping data and then performing calculations within each group.
- Multi-table joins or cross-referencing.
- For tables that require multiple aggregations or logical reasoning across columns, TAPAS might struggle, leading to lower accuracy in such scenarios. For example:
- Input Dependency:
- The model's performance is heavily dependent on the query formulation and table structure. If the table data or the query is poorly designed, ambiguous, or lacks clarity, the model might produce incorrect or irrelevant answers.
- Lack of Explicit Reasoning:
- TAPAS lacks the ability to explicitly reason about hierarchies or relationships within data, which limits its use for tasks requiring deeper insights beyond simple cell-level aggregation.
Example of Limitation:
- Scenario:
- Query: "What is the average number of days for wrestlers holding titles grouped by decades?"
- Table: Contains data for wrestlers and their title-holding years.
- Issue:
- TAPAS would struggle because this query requires grouping by decades and then performing multiple aggregations (averaging within groups). TAPAS lacks the expressivity for such hierarchical processing.