Parallel Database Architecture
Design of Parallel Databases | DBMS
A parallel DBMS is a DBMS that runs across multiple processors or CPUs and is mainly designed to execute query operations in parallel, wherever possible. The parallel DBMS link a number of smaller machines to achieve the same throughput as expected from a single large machine.
In Parallel Databases, mainly there are three architectural designs for parallel DBMS. They are as follows:
- Shared Memory Architecture
- Shared Disk Architecture
- Shared Nothing Architecture
- Hierarchial
Shared Memory Architecture

Figure 1: Shared Memory Architecture
- Processors & disks access common memory
- via a bus, or through an interconnection network.
- Extremely efficient communication between processors
- data in shared memory can be accessed by any processor
- processor can send message to others thru main memory
Bottleneck
- Scalability: Typically, shared memory systems are not scalable beyond a certain number of processors, usually around 32 or 64.
- Resource Contention: Since all processors share the same memory, there is a high chance of contention (or competition) for memory access.
Advantages
- **High Communication Efficiency: **Since all processors access the same memory space, they can share data quickly and easily without the need for complex data exchange protocols. This reduces latency and enhances the speed of communication, making shared memory systems extremely efficient for tasks requiring frequent data sharing.
- Immediate Data Consistency: With shared memory, the data is always in a single place, ensuring immediate consistency.
- Ease of Programming: Shared memory systems simplify parallel programming because developers do not have to manage complex inter-processor communication. The data can be accessed directly from the shared memory, making it easier to write code for tasks that need collaborative processing.
Ideal Use Cases for Shared Memory Systems
- Low to Moderate Parallelism: Shared memory systems work well for applications where lower degrees of parallelism are sufficient, such as tasks that do not require more than 32–64 processors.
- Real-Time Applications: These systems are well-suited to real-time applications, where processors need immediate, synchronized access to shared data.
- Data-Intensive Tasks with Frequent Updates: Shared memory architectures are ideal for applications like online transaction processing (OLTP), where data is frequently updated and needs to be consistent across all processors in real time.
Shared Disk Architecture
In a shared disk architecture, each processor in the system has its own private memory but can access a common pool of disks through an interconnection network.

Figure 2: Shared Disk Architecture
Advantages of Shared Disk Systems
- Fault Tolerance:
- One of the most significant benefits of shared disk architectures is fault tolerance. Since the disks are accessible by all processors, if a processor fails, other processors can take over its tasks without losing access to the data. This makes the system highly resilient, as other processors can continue to process transactions and tasks using the same shared data.
- This fault tolerance is valuable for applications like databases, where continuous access to data is critical. Shared disk systems allow uninterrupted service by enabling other processors to step in if one fails.
-
Scalability with Fewer Memory Bottlenecks: Because each processor has its own memory, there is no memory bus bottleneck as seen in shared memory systems. This separation allows shared disk architectures to scale to a higher number of processors than a shared memory architecture can handle.
-
Centralized Data Management: With all data stored in a shared disk system, data management and updates can be centralized. This is particularly beneficial in applications that require consistent and synchronized data, such as databases, where multiple processors need access to the same information for processing user queries and transactions.
Limitations of Shared Disk Systems
-
Disk Interconnection Bottleneck: The primary bottleneck in shared disk systems occurs at the interconnection network to the disk. As more processors try to access the shared disk simultaneously, the interconnection network can become a point of congestion, slowing down the rate at which data can be retrieved or stored. The interconnection to the disk may be slower than each processor’s private memory access, which can lead to delays when multiple processors need data from the shared disks.
-
Slower Communication: While processors can access the shared disks, the communication speed over the interconnection network is often slower than direct access to local memory. This slower communication can limit the overall speed of processing, especially for tasks that require frequent data access from the disks.
-
Complexity in Data Management: Since all processors can access shared data, managing data consistency and avoiding conflicts can be more complex, especially in environments with high transaction rates. Systems need sophisticated locking and synchronization mechanisms to ensure data integrity.
Scalability
Shared disk architectures are typically more scalable than shared memory systems because they do not rely on a single memory bus. They can support a good number of processors—more than a shared memory system can, but often fewer than a distributed memory system. However, as the number of processors increases, the interconnection network to the disk can still become a bottleneck, which limits scalability beyond a certain point.
Ideal Use Cases for Shared Disk Systems
-
Databases and Transaction Processing: Shared disk systems are widely used in databases and transaction-heavy applications, where fault tolerance and continuous access to shared data are essential. For example, a banking database system could use a shared disk architecture to allow multiple processors to handle transactions, with the reassurance that, if one processor fails, others can pick up the load.
-
Applications Requiring Centralized Data Access: Shared disk systems are ideal for applications where data needs to be centralized and accessible to multiple processors, like in clustered database environments for OLTP (Online Transaction Processing) or OLAP (Online Analytical Processing).
Example
Consider a financial trading platform where multiple processors analyze stock market data. The data is stored in a shared disk that all processors can access. If one processor fails, others continue the analysis without interruption. However, as more processors try to access the shared data simultaneously, there may be delays due to the bottleneck at the interconnection network to the disk.
Shared-Nothing Architecture
In a shared-nothing architecture, each node in the system is fully independent, meaning it has its own processor, memory, and storage (disk). Nodes communicate with each other only through an interconnection network, and no resources—neither memory nor storage—are shared between nodes. This setup is also known as a "node-per-server" or "server-per-node" system, with each node acting as a stand-alone server.

Figure 3: Shared-Nothing Architecture
Advantages of Shared-Nothing Architecture
-
High Scalability: Shared-nothing systems can be scaled up to thousands of processors, as each node is independent and does not rely on shared resources that could become a bottleneck. Adding more nodes enhances the system’s processing power and storage capacity, allowing it to handle larger workloads efficiently.
-
Fault Isolation: In a shared-nothing system, the failure of one node does not directly impact the others because each node is self-contained. This design improves fault tolerance and simplifies maintenance, as faulty nodes can be replaced or repaired without disrupting the rest of the system.
-
Efficient Use of Resources: Since each node manages its own resources, shared-nothing architectures avoid the resource contention issues seen in shared memory or shared disk systems. Each node’s memory and disk resources are dedicated to its own tasks, maximizing resource efficiency.
Drawbacks of Shared-Nothing Architecture
-
Cost of Communication: The primary drawback of shared-nothing systems is the cost of inter-node communication. When nodes need to exchange data, the process involves transferring data across the interconnection network, which can be slower than direct memory access. This communication overhead can reduce efficiency, especially when nodes need frequent access to each other’s data.
-
Non-Local Disk Access: If a node needs to access data stored on another node’s disk, it must request the data over the network. This non-local disk access can significantly slow down processing because accessing data from a remote node is slower than accessing local storage. Additionally, this process involves both the sending and receiving nodes, further increasing overhead.
-
Software Overhead: Sending data between nodes requires software-level coordination at both ends. This involves protocols for data request, transfer, and synchronization, which add complexity to data sharing. The software overhead for these interactions can slow down data processing, particularly in systems with frequent inter-node data exchanges.
Scalability of Shared-Nothing Architecture
Shared-nothing architectures are among the most scalable, capable of expanding to thousands of processors. Since nodes operate independently, there’s no inherent bottleneck that limits the number of nodes. However, the scalability comes with the challenge of efficiently managing and coordinating communication between thousands of independent nodes, which requires sophisticated network design and efficient data management algorithms.
Ideal Use Cases for Shared-Nothing Architecture
-
Data Warehousing and Big Data Analytics: Shared-nothing systems are well-suited to data-intensive applications, such as data warehousing and big data analytics, where large datasets are processed in parallel across many nodes. Each node can analyze its own portion of the data, reducing the need for inter-node communication.
-
Distributed Databases: Shared-nothing architectures are commonly used in distributed databases, where data is partitioned across nodes. Each node can independently handle queries related to its own data partition, improving query performance and enabling high concurrency.
-
Fault-Tolerant Systems: Applications that require high fault tolerance, such as critical transaction processing systems, benefit from shared-nothing designs. Since each node operates independently, the system can continue functioning even if some nodes fail.
Example
Consider a large e-commerce platform that uses a shared-nothing database to manage product listings, customer information, and transaction history. Each node in the system might store data for a subset of the platform’s customers, processing queries and transactions independently. This setup allows the platform to scale up by adding more nodes as its customer base grows, while also providing fault tolerance; if one node goes down, the others can continue operating without disruption.
Hierarchical Architecture
The hierarchical architecture in parallel processing combines elements from shared-memory, shared-disk, and shared-nothing architectures into a multi-level structure that optimizes resource use, communication efficiency, and scalability.
Key Features of Hierarchical Architecture
-
Top-Level Shared-Nothing Architecture: At the highest level, a hierarchical system is organized as a shared-nothing architecture. Each top-level node operates independently, with its own processors, memory, and storage, meaning there’s no resource sharing between these top-level nodes. This design allows the system to scale effectively, as additional nodes can be added with minimal impact on the others.
-
Flexible Lower-Level Nodes: Each top-level node can use either a shared-memory or shared-disk configuration within itself. Here’s how these configurations work within each node:
- Shared-Memory System: Processors within the node access a common memory resource, allowing for quick communication between processors. This setup is suitable for nodes that handle tasks requiring close coordination among processors.
- Shared-Disk System: Each processor within the node has its own memory, but they share access to a common disk resource. This configuration is helpful for high availability and fault tolerance because, if one processor fails, others within the node can continue accessing data on the shared disk.
- Hybrid Systems: Some nodes may be shared-memory, while others may be shared-disk, providing flexibility based on the workload each node is assigned.
-
Distributed Virtual Memory: To simplify management and allow the hierarchical system to function as a cohesive whole, a distributed virtual memory is implemented. This approach makes it appear that all memory across nodes is part of a single, logical memory space, even though physically, each node has its own independent memory.
-
Non-Uniform Memory Access (NUMA): This type of hierarchical architecture is also known as Non-Uniform Memory Access (NUMA). In a NUMA system, the time it takes for a processor to access memory varies depending on the location of the memory. Processors access memory within their node more quickly than they can access memory on another node. NUMA optimizes for performance by placing memory closer to the processors that need it most, reducing access times within nodes and enhancing efficiency.
Advantages of Hierarchical Architecture
-
Scalability: By using a shared-nothing architecture at the top level, hierarchical systems can scale to a large number of nodes. As additional resources are added, the system’s capacity and processing power increase without creating a central bottleneck.
-
Fault Tolerance: Each node operates independently, allowing the system to handle node failures without affecting overall performance. Shared-disk nodes can even continue to function if a processor within the node fails, as other processors can access the shared data.
-
Efficient Resource Use: With distributed virtual memory, each processor can access data from any node, but the system optimizes for local access first. NUMA design ensures that processors get quick access to nearby memory, reducing latency and improving response times for data processing.
Drawbacks of Hierarchical Architecture
-
Complexity in Coordination: Managing a hierarchical structure with different memory-sharing configurations at lower levels can be complex. Balancing the load between shared-memory and shared-disk nodes and managing virtual memory mappings require sophisticated algorithms.
-
Latency in Non-Local Access: While distributed virtual memory allows access to data across nodes, accessing memory in a different node takes longer than accessing local memory. This latency can become significant in applications that frequently require cross-node communication.
Use Cases of Hierarchical Architecture
-
Large-Scale Data Processing: Hierarchical systems work well in environments like scientific simulations, data mining, and analytics where large amounts of data are processed in parallel, and scalability is crucial. NUMA optimizes data access time, making it suitable for workloads requiring high efficiency and speed.
-
Mixed Workloads: For enterprises that need to handle both OLTP (Online Transaction Processing) and DSS (Decision Support System) workloads, a hierarchical architecture can segregate tasks based on processing needs. Shared-memory nodes can be used for OLTP applications that need fast communication, while shared-disk nodes can handle DSS tasks requiring high storage capacity.
-
Fault-Tolerant Systems: In mission-critical applications, such as telecommunications or financial transactions, hierarchical architectures offer high fault tolerance. Redundant nodes ensure that if one fails, others can continue processing without downtime.
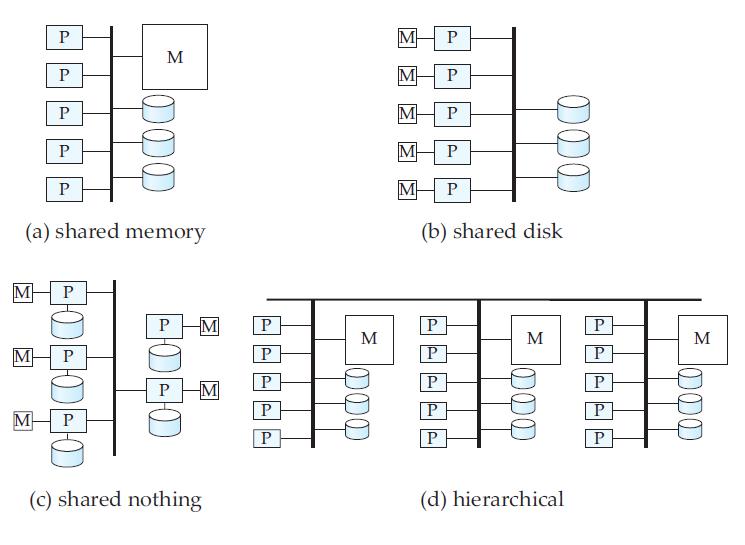
Figure 4: Four different architectures of parallel database systems