Parallel Processing
Parallel Processing Defined
Parallel processing divides a large task into many smaller tasks, and executes the smaller tasks concurrently on several nodes. As a result, the larger task completes more quickly.
Note: A node is a separate processor, often on a separate machine. Multiple processors, however, can reside on a single machine.
Some tasks can be effectively divided, and thus are good candidates for parallel processing. Other tasks, however, do not lend themselves to this approach.
For example, in a bank with only one teller, all customers must form a single queue to be served. With two tellers, the task can be effectively split so that customers form two queues and are served twice as fast-or they can form a single queue to provide fairness. This is an instance in which parallel processing is an effective solution.
By contrast, if the bank manager must approve all loan requests, parallel processing will not necessarily speed up the flow of loans. No matter how many tellers are available to process loans, all the requests must form a single queue for bank manager approval. No amount of parallel processing can overcome this built-in bottleneck to the system.
Large-scale parallel database systems is needed:
- to store large volumes of data
- to process time-consuming decision-support queries
- to provide high throughput for transaction processing
Processing of single independent tasks
Figure 1 and Figure 2 contrast sequential processing of a single parallel query with parallel processing of the same query.

Figure 1: Sequential Processing of a Large Task
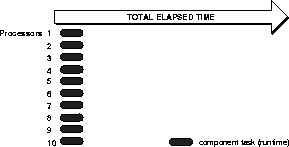
Figure 2: Parallel Processing: Executing Component Tasks in Parallel
- In sequential processing, the query is executed as a single large task.
- In parallel processing, the query is divided into multiple smaller tasks, and each component task is executed on a separate node.
Processing of multiple independent tasks
Figure 3 and Figure 4 contrast sequential processing with parallel processing of multiple independent tasks from an online transaction processing (OLTP) environment.
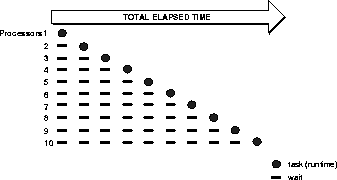
Figure 3 Sequential Processing of Multiple Independent Tasks

Figure 4 Parallel Processing: Executing Independent Tasks in Parallel
- In sequential processing, independent tasks compete for a single resource. Only task 1 runs without having to wait. Task 2 must wait until task 1 has completed; task 3 must wait until tasks 1 and 2 have completed, and so on. (Although the figure shows the independent tasks as the same size, the size of the tasks will vary.)
- By contrast, in parallel processing (for example, a parallel server on a symmetric multiprocessor), more CPU power is assigned to the tasks. Each independent task executes immediately on its own processor: no wait time is involved.
Problems of Parallel Processing
Effective implementation of parallel processing involves two challenges:
- structuring tasks so that certain tasks can execute at the same time (in parallel)
- preserving the sequencing of tasks which must be executed serially
Characteristics of a Parallel System
A parallel processing system has the following characteristics:
- Each processor in a system can perform tasks concurrently.
- Tasks may need to be synchronized.
- Nodes usually share resources, such as data, disks, and other devices.
Parallel Processing for SMPs and MPPs
Parallel processing architectures may support:
- SMP: single memory systems-also known as symmetric multiprocessing (SMP) hardware, in which multiple processors use one memory resource
- MPP: clustered and massively parallel processing (MPP) hardware, in which each node has its own memory
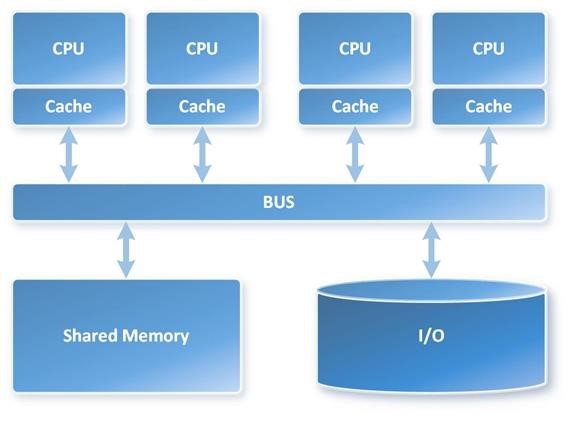
Figure 5: Symmetric Multi Processing SMP
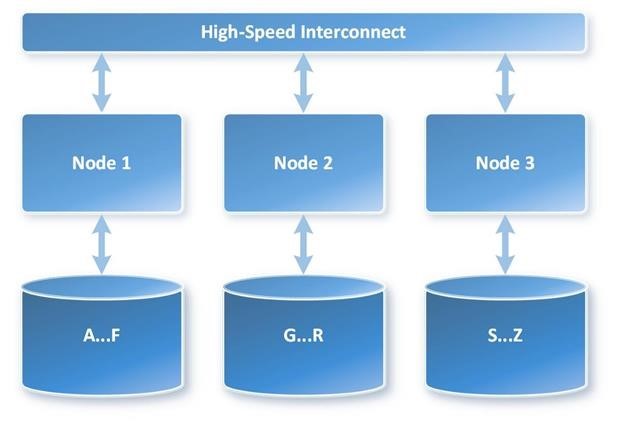
Figure 6: MPP with Shared-nothing Architecture
Parallel Processing for Integrated Operations
Parallel processing in database software is essential for handling a variety of workloads efficiently. In integrated operations, a parallel database needs to balance different types of applications, including Online Transaction Processing (OLTP), Decision Support Systems (DSS), and combinations of both. Each of these applications has unique requirements:
-
OLTP Applications: OLTP workloads consist of many short transactions with relatively low CPU and I/O demands. These applications require fast, efficient processing for tasks like inventory updates, financial transactions, or user interactions, typically requiring high throughput for smaller tasks.
-
DSS Applications: DSS workloads involve long, complex transactions that are CPU- and I/O-intensive, often due to the need for extensive data analysis, reporting, or forecasting. DSS applications are typically used for strategic decision-making and therefore require substantial processing power and memory to handle large datasets.