SPIDER 2.0: CAN LANGUAGE MODELS RESOLVE REAL-WORLD ENTERPRISE TEXT-TO-SQL WORK-FLOWS?
Spider-Agent
Spider-Agent is a language model agent that iteratively interacts with a database and modifies its code (SQL/Python) based on observations to generate the correct SQL query. It combines a question, database interface, and codebase to refine the SQL query until the correct result is achieved
Spider 2.0 Benchmark
Spider 2.0 is an advanced version of the Spider benchmark, which is used to evaluate text-to-SQL models. It provides a more challenging setting by incorporating real-world, complex databases and testing the model’s ability to generate SQL queries across different databases with contextual understanding, schema diversity, and error resolution capabilities. It also includes both SQL and Python code generation for more interactive tasks.
Detailed Explanation of the Introduction
The introduction of the paper "SPIDER 2.0: CAN LANGUAGE MODELS RESOLVE REAL-WORLD ENTERPRISE TEXT-TO-SQL WORK" outlines the significance of automated code generation, particularly in the context of transforming natural language into SQL queries. Here are the key points discussed:
-
Importance of Automated Code Generation: The introduction emphasizes that automated code generation is essential for bridging the gap between humans and data. It helps individuals perform complex tasks more efficiently, especially when dealing with relational databases where SQL is the primary interface for data interaction
-
Role of Semantic Parsing: Semantic parsing, or text-to-SQL, is highlighted as a critical technology that aids data analysts in executing routine queries and managing data workflows. This technology significantly reduces repetitive tasks and lessens the workload on programmers
-
Capabilities of Large Language Models (LLMs): The introduction notes that LLMs, particularly those based on GPT-4, have shown impressive performance in generating SQL queries from natural language, achieving high execution accuracy on classic benchmarks like Spider 1.0 and BIRD
-
Limitations of Current Models: Despite their success on benchmark datasets, LLMs often struggle with real-world complexities. The datasets they are trained on typically feature simplified SQL queries and limited database structures, which do not reflect the intricacies of actual enterprise databases
-
Complexity of Real-World Databases: Real-world databases are characterized by diverse SQL dialects, large schemas with thousands of columns, and complex nested structures. The introduction stresses that enterprise-level text-to-SQL workflows require a deep understanding of database metadata and the ability to navigate various SQL dialects and project codebases
-
Need for a New Benchmark: The paper introduces Spider 2.0 as a new benchmark designed to reflect real-world data workflows. It consists of 595 complex tasks derived from actual enterprise applications, showcasing the need for models that can handle intricate SQL queries and data transformations
-
Task Complexity: The tasks in Spider 2.0 require models to interact dynamically with databases, generate multiple SQL queries, and perform complex reasoning. This level of complexity is significantly higher than what previous benchmarks demanded, indicating a substantial gap in current LLM capabilities
-
Evaluation of Current Models: The introduction concludes by noting that existing models, such as the o1-preview based code agent framework, have shown poor performance on Spider 2.0, achieving only 15.1% success compared to much higher rates on simpler benchmarks. This highlights the urgent need for advancements in LLMs to meet the demands of real-world enterprise applications
Overall, the introduction sets the stage for the challenges and objectives of the Spider 2.0 benchmark, emphasizing the need for improved models capable of handling the complexities of enterprise-level text-to-SQL tasks.
Detailed Explanation of Figure 1
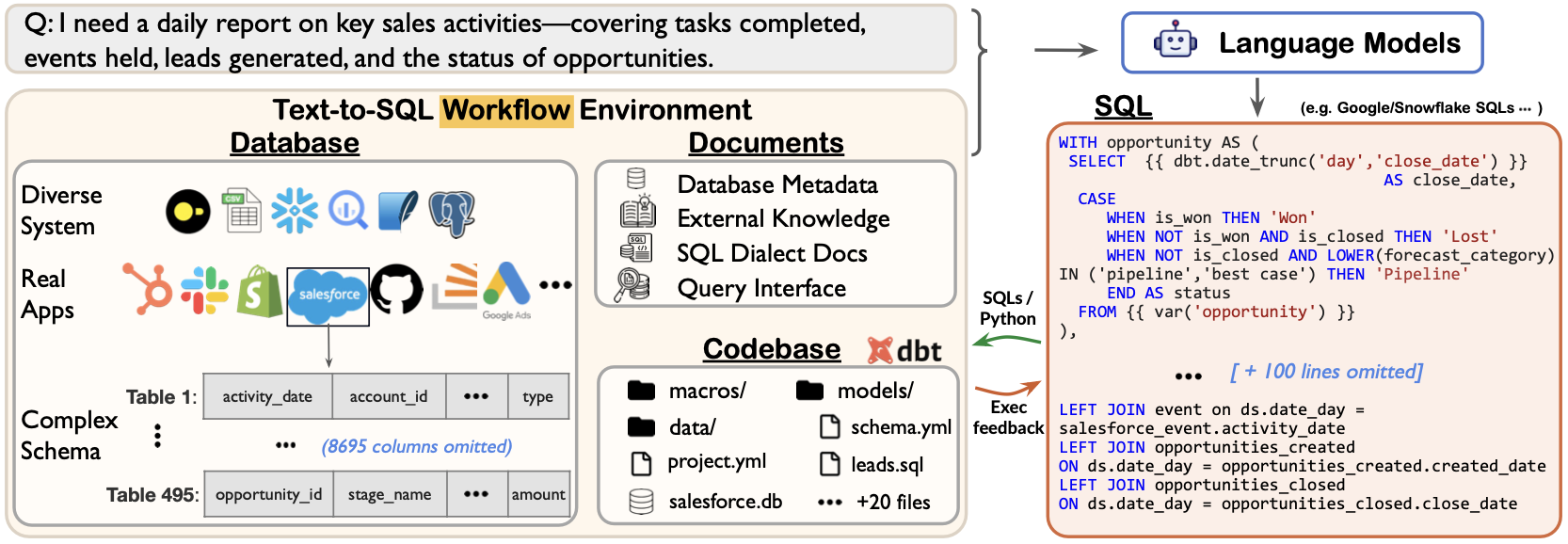
Figure 1 in the paper "SPIDER 2.0: CAN LANGUAGE MODELS RESOLVE REAL-WORLD ENTERPRISE TEXT-TO-SQL WORK" illustrates the evaluation framework and the workflow involved in the Spider 2.0 benchmark.
Here are the key components and insights derived from the figure:
-
Overview of the Evaluation Framework: The figure provides a visual representation of how the Spider 2.0 framework operates. It outlines the process from the initial natural language query to the final SQL query generation, emphasizing the steps involved in transforming user input into executable SQL commands.
-
Natural Language Input: At the starting point, the user provides a natural language query. This input is crucial as it sets the context for the SQL generation process. The complexity of the input can vary significantly, reflecting real-world scenarios where users may have diverse requests related to data retrieval and manipulation.
-
Understanding Database Metadata: The next step involves the model's interaction with the database metadata. This is a critical phase where the model must comprehend the structure of the database, including tables, columns, and relationships. The ability to accurately interpret this metadata is essential for generating correct SQL queries, especially in databases with complex schemas and nested types
-
SQL Query Generation: Following the understanding of the database schema, the model generates SQL queries. This step is where the model's capabilities are tested, as it must translate the natural language input into a syntactically and semantically correct SQL statement. The figure likely highlights the challenges faced during this translation, particularly in cases where the input is ambiguous or requires multi-step reasoning.
-
Execution of SQL Queries: After generating the SQL queries, the next phase involves executing these queries against the database. This step is crucial for validating the correctness of the generated SQL. The figure may depict how the execution results are compared against expected outcomes to assess the model's performance.
-
Feedback Loop for Improvement: The figure may also illustrate a feedback mechanism where the results of the SQL execution inform further iterations of query generation. This iterative process is vital for refining the model's understanding and improving its accuracy over time.
-
Challenges Highlighted: The figure likely emphasizes the challenges that arise during each phase of the workflow, particularly in handling complex queries, understanding nested schemas, and ensuring that the generated SQL aligns with the user's intent. These challenges are central to the motivation behind developing the Spider 2.0 benchmark, as they reflect the real-world difficulties faced by language models in enterprise settings
In summary, Figure 1 serves as a comprehensive overview of the Spider 2.0 evaluation framework, detailing the workflow from natural language input to SQL execution, while highlighting the complexities and challenges inherent in real-world text-to-SQL tasks.
Key Differences Between Spider 2.0 and Spider 2.0-lite
The paper outlines several important differences between Spider 2.0 and Spider 2.0-lite, which are summarized as follows:
-
Task Complexity:
- Spider 2.0: Designed to reflect real-world enterprise SQL workflows, requiring models to interact with diverse sources, generate multiple SQL queries, and perform complex data transformations and analyses. It involves understanding and searching through database metadata and project-level codebases
- Spider 2.0-lite: Simplified version that focuses on direct text-input-to-SQL-output challenges. It is easier to work with using current advanced text-to-SQL parsers, but it does not require the same level of interaction with complex environments as Spider 2.
-
Data and Context Access:
-
Spider 2.0: Models have access to a comprehensive set of information, including execution feedback and project-level documentation, which aids in generating accurate SQL queries
-
Spider 2.0-lite: Models have access to less information, which makes the task more straightforward but also limits the complexity of the queries that can be generated
-
-
Performance Metrics:
-
Spider 2.0: Reports a significantly lower success rate for models, with only 15.1% of tasks successfully solved, indicating the high difficulty level of the tasks
-
Spider 2.0-lite: Although it is easier, even the most advanced text-to-SQL parsers could only address 9.3% of the questions, which highlights the challenges present in both settings but suggests that Spider 2.0-lite is more manageable
-
-
Question Naturalness vs. Unambiguity:
-
Spider 2.0: Questions are crafted to be more natural due to the availability of context and predefined files, which guide the answers
-
Spider 2.0-lite: Prioritizes unambiguity, ensuring that the task instructions are clearer and more straightforward, which may lead to less natural phrasing
-
-
Schema Handling:
-
Spider 2.0: Involves complex schemas with nested structures, which pose significant challenges for language models in understanding and generating SQL queries
-
Spider 2.0-lite: While it still involves schema understanding, the complexity is reduced, making it easier for models to generate SQL queries without the added difficulty of nested schemas
-
In summary, Spider 2.0 is a more complex and realistic benchmark that requires deeper interaction with various data sources and project-level contexts, while Spider 2.0-lite simplifies the task, making it more accessible for current text-to-SQL parsers but at the cost of some complexity and naturalness in the questions posed.
Analysis of the Gold SQL and Predicted SQL
Question Explaination (Question 1)
- Divide the trips into 10 groups based on duration.
- For each of the 10 groups (quantiles), calculate:
- How many trips are in that group.
- What the average fare is for the trips in that group.

Analysis of the Gold SQL and Predicted SQL
- Quantile Calculation:
- Gold SQL: Divides the trips into quantiles based on duration in minutes (NTILE(10) OVER (ORDER BY duration_in_minutes)).
- Predicted SQL: Divides the trips into quantiles based on trip seconds (NTILE(10) OVER (ORDER BY trip_seconds)), which is not the same as dividing based on the trip duration in minutes.
- Incorrect Filtering:
- Gold SQL: Correctly filters trips where duration is between 1 and 50 minutes.
- Predicted SQL: Filters trips based on trip seconds between 60 and 3000, which does not correctly represent the intended 1 to 50 minutes range. The conversion from seconds to minutes is incorrect.
- Grouping:
- Gold SQL: Groups the data by duration in minutes (GROUP BY duration_in_minutes), ensuring that trips with similar durations are grouped together.
- Predicted SQL: Groups by quantile derived from trip seconds, not by duration.
- Impact of Errors:
- In the Predicted SQL, quantiles are based on the number of trips rather than duration, leading to incorrect grouping. This could result in incorrect analysis of the total number of trips and average fare for each quantile, as the trip durations are not the primary basis for the quantiles.
Question Explaination (Question 2)
- Task: Group users by the week they first used the app, starting from July 2, 2018.
- Group Naming: Each group should be named by the Monday date of the week when the user first used the app.
- Time Range: The groupings start from July 2, 2018, which is the Monday of the first week.
- Specific Group: Identify the group that corresponds to the fourth week after July 2, 2018.
- Output Format: Provide the answer in the format of a date: 'YYYY-MM-DD'.
Key Steps to Implement in SQL:
- Calculate the Week Start Date: Identify the Monday of the week each user first used the app.
- Group Users by Week: Group users based on their first usage week.
- Identify the Fourth Week: Find the group whose start date is the Monday of the fourth week after July 2, 2018.
- Return the Date: Output the Monday date for the fourth week in the required format.

Key Issues with the Predicted SQL:
-
Incorrect Filtering of Week 4: The predicted SQL tries to filter users based on a fixed 21–27 days range after their first session. However, the fourth week should be considered as a whole week (7 days), typically represented by week 4 starting from the 22nd to the 28th day, not a 7-day window between 21 and 27 days.
-
Wrong Grouping Logic: The DATE_DIFF filtering in the predicted SQL does not correctly segment users by weekly cohorts based on their first session. The correct approach would involve grouping by week since first touch and calculating the retention or activity for week 4 in that cohort.
-
Lack of Cohort Calculation: The Gold SQL groups users into cohorts based on the first session week using NTILE and then calculates retention (i.e., whether they are still active in week 4). The predicted SQL doesn’t use this approach and instead just filters for users within a specific range of days after their first session, leading to a misinterpretation of what week 4 should represent.
Analysis of Different Experimental Settings (Summary)
- Reference Plan Improves SQL Generation:
- Detailed annotations in the reference plan provide step-by-step instructions on how to generate SQL queries.
- The reference plan decouples the database exploration from the SQL generation process, improving clarity and accuracy.
- This approach resulted in a 4% improvement in SQL generation performance for DAIL-SQL.
- Example: Using the step-by-step plan (App.B.1), complex queries can be broken down, and generating SQL becomes more structured and effective.
- 18.4% of instances solved correctly using o1-preview, which excels at code generation. This suggests some complex instances benefit from a step-by-step approach, possibly involving multiple CTE (Common Table Expressions) clauses.
- Providing Oracle Functions for Performance:
- Including Oracle function documentation led to a slight performance improvement.
- Spider 2.0 and Spider 2.0-lite involve SQL dialects from multiple database systems. Providing relevant function documentation for each SQL dialect helps avoid performance issues due to missing syntax knowledge.
- Despite the documentation, model performance improvement was slight, indicating that models can already select appropriate functions and understand their basic usage.
- Challenge: The critical issue lies in accurately using these functions to match the user's intent (as shown in Fig. 7(a)).
- Few-shot Prompting Has Little Impact:
- Spider 2.0-lite doesn't have separate train and dev sets, so 9 representative examples were manually chosen to serve as few-shot examples.
- These examples were selected for their distinct characteristics, such as:
- Multiple CTE or nested queries.
- Complex data processing requirements.
- Result: Few-shot in-context learning showed only marginal improvements in performance (see Tab. 10).
- Possible reasons:
- The pre-training data used for text-to-SQL tasks is simplistic compared to the complexity of few-shot examples. ( )Extensive schema prompts may hinder the model's ability to properly process and learn from few-shot examples.