Parallel Database Systems
Parallel database systems are designed to process large amounts of data efficiently by distributing the workload across multiple computing resources. These resources generally include multiple processors and multiple disks, all connected through a high-speed interconnection network. This architecture allows the system to perform complex computations and handle large datasets more quickly than single-processor systems by breaking tasks into smaller, parallelizable units. Below are the main components and types of parallel systems:
Components of Parallel Database Systems
-
Multiple Processors: A parallel database system relies on multiple CPUs, or processors, to divide the computational load. These processors can work simultaneously on different parts of a query or a task, leading to faster query execution and higher throughput. The number of processors and how they communicate greatly affect the system's performance.
-
Multiple Disks: Distributing data across multiple disks enables faster data retrieval and storage by allowing simultaneous read and write operations. In parallel systems, data is usually partitioned across the disks, allowing the system to access different parts of the data concurrently, which reduces input/output (I/O) bottlenecks.
-
High-Speed Interconnection Network: The processors and disks in a parallel database system are connected by a fast network that allows for quick communication. This network plays a crucial role in ensuring data consistency and coordination across the different processors. Depending on the system, this can be implemented with technologies such as high-speed buses, switches, or fiber optic networks, enabling processors and disks to share data and resources efficiently.
Types of Parallel Machines
Parallel database systems are typically categorized based on the granularity of parallelism and the number of processors used. This granularity can be either coarse-grain or fine-grain:
Coarse-Grain Parallel Machines:
- In a coarse-grain parallel machine, there are a relatively small number of powerful processors. Each processor is more capable and can handle larger chunks of data or processing tasks. These machines are suited for applications that can benefit from a high level of performance per processor, as the fewer but stronger processors can tackle significant portions of tasks independently.
- Coarse-grain systems are commonly used in enterprise applications where intensive computations are required but with relatively less parallelization across numerous processors.
Massively Parallel Processing (MPP) or Fine-Grain Parallel Machines:
- Massively parallel, or fine-grain, parallel systems consist of hundreds or even thousands of smaller processors working together. These processors may not be individually powerful, but collectively they can process extremely large datasets by dividing tasks into very small parts.
- Each processor may handle a tiny fraction of the overall workload, making these systems suitable for applications requiring extensive parallelism, such as data mining, scientific simulations, and large-scale data processing (e.g., in big data and analytics).
- In MPP systems, data is typically spread across many processors and disks, each handling its portion of the data. The high degree of parallelism allows for significant scalability, meaning the system can be expanded by adding more processors as needed.
Performance Measures
In performance measurement for computing systems, two key metrics—throughput and response time—are essential in evaluating the efficiency and speed of a system in processing tasks. These metrics are particularly relevant in parallel processing, database systems, and other high-performance computing environments. Here’s a detailed look at each:
-
Throughput
- Definition: Throughput measures the number of tasks a system can complete within a specific timeframe (e.g., per second or per minute). It is an indicator of how much work the system can handle concurrently and is typically expressed as tasks per second, transactions per minute, or similar units.
- Relevance: Throughput is crucial for applications where a large number of tasks need to be processed continuously, such as in high-volume transaction processing, web servers handling multiple requests, or data processing in parallel computing.
- Example: In a database system, if the system can process 100 queries per second, then its throughput is 100 queries per second. Higher throughput means the system can handle a greater load, which is particularly beneficial for environments requiring constant processing of a high volume of tasks.
-
Response Time
- Definition: Response time is the time it takes to complete a single task from the moment it is requested. It includes any delays from the start of the request to the completion of the task. Essentially, it’s how long the user has to wait for the result.
- Relevance: Response time is critical for applications where users expect quick feedback on individual requests, such as in interactive applications, web browsing, online transactions, or real-time data analysis. Lower response times lead to better user experiences, especially in time-sensitive environments.
- Example: If a user submits a query to a database and it takes 2 seconds to receive the results, the response time for that query is 2 seconds. A faster response time means the system can provide results more quickly, which is essential in applications like online banking or e-commerce where delays can frustrate users.
Measure of performance goals
Speed-Up
Speedup is the effect of applying an increasing number of resources to a fixed amount of work to achieve a proportional reduction in execution times:
speedup = small system elapsed time / large system elapsed time
- Speedup is linear if equation equals N.
- Speedup results in resource availability for other tasks.
- For example, if queries usually take ten minutes to process in one CPU and running in parallel in more CPUs reduces the time, then additional queries can run without introducing the contention that might occur were they to run concurrently.
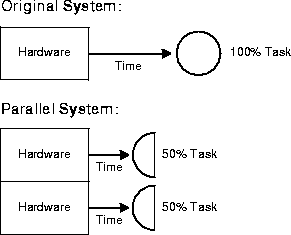

- Linear Speedup Speedup is linear if the speedup is N. That is, the small system elapsed time is N times larger than the large system elapsed time (N is number of resources, say CPU). For example, if single machine does the job in 10 seconds and if parallel machine (10 single machines) does the same job in 1 second, then the speedup is (10/1)=10 (refer to the equation above) which is equal to N which is the size of larger system. The speedup is achieved due to the 10 times powerful system.
- Sub-Linear Speedup Speedup is sub-linear if speedup is less than N (which is usual in most of the parallel systems).
Scale-Up
Scaleup is the ability to keep the same performance levels (response time) when both workload (transactions) and resources (CPU, memory) increase proportionally.
scaleup = small system small problem elapsed time / big system big problem elapsed time
- Scaleup: increase the size of both the problem and the system
- For example, if 50 users consume close to 100 percent of the CPU during normal processing, then adding more users would cause the system to slow down due to contention for limited CPU cycles. However, by adding more CPUs, we can support extra users without degrading performance.
- Scale up is linear if equation equals 1.

- Scaleup increases the Throughput, i.e, number of tasks completed in a given time increased.
- Linear Scaleup Scaleup is linear if the resources increase in proportional with the problem size (it is very rare). According to the equation given above, if small system small problem elapsed time is equal to large system large problem elapsed time, then Scaleup = 1 which is linear.
- Sub-linear Scaleup Scaleup is sub-linear if large system large problem elapsed time is greater than small system small problem elapsed time, then the scaleup is sub-linear.
What is Transaction Scaleup?
- Numerous small queries are constantly being submitted to a single, shared database by multiple users. These queries are typically fast, short-lived transactions like updates, inserts, or data retrieval requests, such as those in an e-commerce site (updating inventory or retrieving product details) or a banking application (checking balances or processing transactions).
- To maintain performance as the number of users grows, the system needs to handle both more requests and more data. For example, a growing user base means more queries per second, and an expanding dataset means each query potentially takes longer to execute.
- Scaling up the system often involves using an N-times larger computer—in this case, referring to a computing setup with more resources, such as more processors or increased memory, which allows for faster and more efficient handling of larger workloads.
Why Parallel Execution is Well-Suited for Transaction Scaleup
Parallel execution is particularly effective for transaction scaleup due to the following reasons:
- Independence of Transactions: Small transactions, especially in OLTP (Online Transaction Processing), are often independent of one another. This independence allows them to be processed in parallel by different processors without waiting for other transactions to complete.
- Distributed Data Access: By partitioning data across multiple disks or servers, each processor can access its designated data portion, reducing contention and accelerating query execution.
- Efficient Resource Utilization: With parallel processing, the system can divide the workload across multiple CPUs and memory resources, enabling it to handle many requests simultaneously. This ensures the system can maintain high throughput even as the transaction load grows.
What are the reasons for Sub-linear performance of speedup and scaleup
Following are the major factors which affect the efficient parallel operation and can reduce both speedup and scaleup.
-
**Startup costs. ** For every single operation which is to be done in parallel, there is an associated cost involved in starting the process. That is, breaking a given big process into many small processes consumes some amount of time or resources. For example, a query which tries to sort the data of a table need to partition the table as well as instructing various parallel processors to execute the query before any parallel operation begins.
-
Example:
SELECT * FROM Emp ORDER BY Salary;
This query sorts the records of Emp table on Salary attribute. Let us assume that there are 1 million employees, so one million records. It will consume some time to execute in a computer with minimal resources. If we would like to execute the query in parallel, we need to distribute (or redistribute) the data into several processors (in case of Shared Nothing Architecture), also, we need to instruct all the processors to execute the query. These two operations need some amount of time well before any parallel execution happens.
-
Interference Since processes executing in a parallel system often access shared resources, a slowdown may result from the interference of each new process as it competes with existing processes for commonly held resources, such as a system bus, or shared disks, or even locks. Both speedup and scaleup are affected by this phenomenon.
-
Skew When breaking down a single task into number of parallel small tasks, it is very hard to make them equal in size. Hence, the performance of the system depends on the slowest CPU which processes the larger sub-task. This type of uneven distribution of a job is called skew. For example, if a task of size 100 is divided into 10 parts, and the division is skewed, there may be some tasks of size less than 10 and some tasks of size more than 10; if even one task happens to be of size 20, the speedup obtained by running the tasks in parallel is only five, instead of ten as we would have hoped.